新しいデータモデルを作成する
このトピックでは、新しいデータモデルを作成する方法とそのプロパティを設定する方法について説明します。
新しいデータモデルを作成するには、2つの方法があります。データモデルセクションのホームページにある[+新しいデータモデル(+ Data model)]タイルを使用する方法と、ファーストトラックツールを使用する方法です。
新しいデータモデルを作成するには、[+データモデル(+ Data model)]タイルを使用して、次のように進めます。
- データモデルセクションのトップページで[+データモデル(+ Data model)]タイルをクリックします。
- データモデルタイルとナビゲーション左パネルに表示される、データモデルの名前を入力します。詳細は、データモデルワークスペースを参照してください。
- 後でアップロードまたはインポートするデータの時間範囲を定義します。
- 後で作成するキューブのディメンションとして使用する時間エンティティを有効にします。詳細については、時間範囲と時間エンティティの項を参照してください。
- 時間エンティティの説明の言語(月の名称など)を定義します。
- [変更を保存(SAVE CHANGES)]をクリックしてデータモデルを作成します。
BoardのデータモデルはすべてUnicodeベースであるため、日本語、中国語、韓国語などのすべての2バイト言語に対応することができます。
データモデル名は一意でなければなりません。
データモデル名には、「\ / : * ? " < > | €」を除くすべてのUnicode文字を含めることができます。
以下はデータモデル名として指定することはできません。
- CON, PRN, AUX, NUL
- COM1, COM2, COM3, COM4, COM5, COM6, COM7, COM8, COM9
- LPT1, LPT2, LPT3, LPT4, LPT5, LPT6, LPT7, LPT8, LPT
時間範囲と時間エンティティ
新しいデータモデルを作成する際には、データの時間範囲を定義する必要があります。この初期設定は、既存のデータライフスパンを基にし、さらに計画目的の為に必要な将来の範囲まで拡張しておく必要があります。
例えば、現在の年が2021年で、その3年前までのデータがある場合、新しいデータモデルの最適な時間範囲は、2018年から2022年になります。この期間には、予算編成のための1年分の余裕も含まれています。
翌年には、2019年から2023年にかけての予算編成のためにタイムレンジをシフトすることもできますし、2019年から2022年にかけて、もはや関連性のない過去のデータを1年分削除してシフトすることも可能です。
時間範囲の最小長は1年で、この場合、開始年と終了年は同じです。
時間範囲の最大範囲は110年で、最も古いものは1990年、最も新しいものは2100年です。
このセクションでは、カスタム時間エンティティを定義し、時間エンティティ間の関係を設定することもできます。時間エンティティについては、時間範囲のセクションで詳しく説明します。
時間範囲はいつでも変更可能ですが、一部の変更を行う場合は追加のデータ管理作業が必要となります。
以下の変更はいつでも可能で、データの再読み込みは必要ありません。
- 終了年を数年先へ変更
- 時間エンティティの追加または削除
以下の修正は、データモデルを最も効率的な方法で再構築するために、キューブ内のすべてのデータをクリアします。
- 開始年の変更(期間の拡張 もしくは 過去の期間を削除)
- 終了年の短縮(終了年を縮めてデータを削除)
データの一部または全部を保護するためには、まずデータモデルをテキストファイルに出力し、時間範囲を変更後に再読み込みする必要があります。
週
週エンティティを有効にする場合、週の最初の日(デフォルトは月曜日)を定義し、以下の表に示す4つの規約のうち1つを選択して、年の最初の週を定義します。
| 値 | 説明 |
| 最初の4日 | その年に属する日が4日以上ある最初の週を、その年の第1週とします。このオプションを選択すると、月曜日から始まる週は、以下でさらに説明するISO 8601標準に対応します。 |
| 最初の1週すべて | その年に属する日が7日間(月曜日から日曜日まで)ある最初の週を、第1週とします。 |
| 1月1日 | 1月1日の属する週を第1週とします。 |
| 以前のBoardバージョン | Boardバージョン4.x以前で採用された規約です。バージョン4.x以前で構築されたBoardデータモデルとの互換性が必要な場合はこのオプションを選択します。 |
最初の3つのオプションのいずれかを選択すると、nnとYYの変数を使用して、週エンティティの各メンバーの説明をカスタマイズできます(nnとYYはそれぞれ週番号と年を表す)。カスタムの説明は15文字以内で設定可能です。
例
| 構文 | 結果 |
|
Week nn/YYYY |
Week 01/2021, Week 02/2021, etc. |
|
W.nn of YY |
W.01 of 21, W.02 of 22, etc. |
|
Week nn of YYYY |
Week 01 of 2021, Week 02 of 2021, etc |
[以前のBoardバージョン(Board Previous Version)]を選択した場合、週エンティティの各メンバーの説明について、以下の追加オプションがあります。
- Desc. = Week nr. このオプションを選択すると、週エンティティの各メンバーの説明として、カレンダー週番号が使用されます。例:[W01]、[W02]など。
- Desc. = Date. このオプションを選択すると、週エンティティの各メンバーの説明として、その週の最終日の日付が表示されます。例:01/03/2021、01/10/2021、など。
両方のオプションを有効にすると、週エンティティの各メンバーの説明には、両方の情報が含まれます。例:[W01] 01/03/2021, [W02] 01/10/2021, など。
ISO 8601規格:追加情報
ISO 8601「データ要素及び交換形式-情報交換-日付及び時刻の表現」ISO 8601 : 1988 (E) 3.17項:「日付及び時刻の表現」
週,暦:暦年内の7日間で、月曜日から始まり、暦年内の序数で識別される。グレゴリオ暦では、1月4日を含む週がこれに相当する。
これは、暦の週に関するこれらの規則を適用することで実現できる。
- 1年を52または53の暦週で分割する。
- 1週間は7日間。月曜日は1日目、日曜日は7日目。
- 1年の最初の暦週は、少なくとも4日間を含む週である。
- ある年が日曜日に終了しない場合、その年の1~3日目の最終日が来年の第1暦週に属するか、来年の最初の1~3日目が今年の最終暦週に属する。
- 木曜日に開始または終了する年のみ、53暦週を有する。
四半期
会計年度エンティティが有効な場合、標準的なカレンダー四半期にこだわらず、会計年度を参照することができます。
nn、YY、yyの各変数を使用して、四半期エンティティの各メンバーの説明をカスタマイズすることができます。
- 会計年度エンティティが無効の場合、nnは四半期番号、YYは年を表します。
- 会計年度エンティティが有効な場合、yyは会計年度の開始暦年を表し、YYは会計年度の終了暦年を表します。
カスタムの説明は15文字以内で設定可能です。
例
| 構文 | 会計年度が有効 | 結果 |
|
Qnn of YYYY |
No | Q1 if 2021, Q2 of 2021, etc. |
|
Q.nn yy-YY |
Yes | Q.1 20-21, Q.2 20-21, etc. |
|
Q.nn of FY yy-YY |
Yes | Q.1 of FY 20-21, Q.2 of FY 20-21, etc. |
会計年度
会計年度エンティティを有効にする場合、月リストから開始月を定義します(デフォルト値は1月です)。
yy変数とYY変数(それぞれ会計年度の開始暦年と終了暦年を表す)を使用して、エンティティの各メンバーの説明をカスタマイズできます。
カスタムの説明は15文字以内で設定可能です。
2018年から2021年までの時間範囲を使用した例:
| 構文 | 結果 |
|
yy-YY |
18-19, 19-20, 20-21 |
|
yyyy to YYYY |
2018 to 2019, 2019 to 2020, 2020 to 2021 |
|
F.Y. yy-YY |
F.Y. 18-19, F.Y. 19-20, F.Y. 20-21 |
会計年度エンティティが有効な場合、会計年度または標準のカレンダー年に基づいて Yearly Cumulated Value機能 を適用できます(この場合、Yearly Cumulated Value機能の横に専用のチェックボックスが自動的に表示されます)。
データファーストトラックツール
データファーストトラックは、データセットを読み込んですぐに分析できるセルフサービス型のデータディスカバリーツールで、データ準備、データモデリング、ブレンド、マッシュアップを自動化します。
元のデータセットは、ExcelやCSVファイル、SQLテーブルやビューです。また、クラウドベースのリポジトリなど、他のデータソースに配置することも可能です。
データファーストトラックは、与えられたデータソースから、キューブ、エンティティ(ディメンション)、関係の候補を自動的に検出します。そして、既存または新規のデータモデルにこれらのオブジェクトを作成し、データをロードします。
データファーストトラックは、あらゆるビジネス・ユーザーに「セルフサービス・データ・ディスカバリー」の体験を提供し、ITユーザーやビジネス・アナリストがすぐにプロトタイピングを開始できるように設計されています。
データファーストトラックは、次のような場合に特に有効です。
- 新しいプラットフォームでゼロから始める場合、新しいデータモデルを素早く作成し、すぐに分析を開始したい
- 既存のデータモデルに新しいデータセットを迅速かつ簡単に追加したい
データファーストトラックツールは、開発者(Developer)ライセンスまたはパワーユーザー(Power user)ライセンスを持つユーザーだけが利用できます。
データファーストトラックツールを使用して新しいデータモデルを作成するには、データモデルホームページのデータファーストトラック(Fast Track)タイルをクリックし、ウィザードにアクセスします。
データファーストトラックウィザードに入ったら、次のように進みます。
- ステップ 1 - データソース(DATA SOURCE) 4つのオプションから接続するデータソースの種類をクリックします。
- ローカルファイル:ローカルのデータストレージを参照し、BoardデータモデルにロードするASCIIファイルを選択することができます。
- リモートファイル:Boardサーバーが動作しているマシンのディレクトリを開き、BoardデータモデルにロードするASCIIファイルを選択することができます。このオプションはオンプレミスのお客様を対象としています
- 関係ソース:ODBCまたはOLEDB接続でリレーショナルデータソースに接続することができます。既存の接続設定とBoardデータモデルにロードしたいテーブル/ビューを選択し、必要に応じてSQL文を編集し、完了したらOKをクリックします。
- その他のデータソース:ODATA/RESTやクラウドデータソースに接続することができます。既存の接続設定を選択し、Boardデータモデルにロードするテーブル/ビューのラジオボタンにチェックを入れ、完了したらOKをクリックします。
完了したら、右矢印ボタンをクリックします
-
ステップ2 - データモデル(DATA MODEL) 2つのオプションからキューブにどのようにデータを保存するかを選択します。
完了したら、右矢印ボタンをクリックします。-
対象となるデータモデルを選択するか、その場で新しいデータモデルを作成します。
-
シンプルなフラット構造で作成:キューブのディメンション(エンティティ)が関係を持たないようにソースデータを統合します。このオプションは、データのアップロード段階で、データファーストトラックツールが関係を作成しないようにします。
-
データ内の関係を検索し階層を作成:キューブにソースデータを統合しながら同時に関係を作成します。
-
-
ステップ3 - 準備(PREPARE) データソースが自動的に解析され、下の画面のようにキューブ、ディメンション(エンティティ)、および関係の候補が検出されます。
完了したら、右矢印ボタンをクリックします。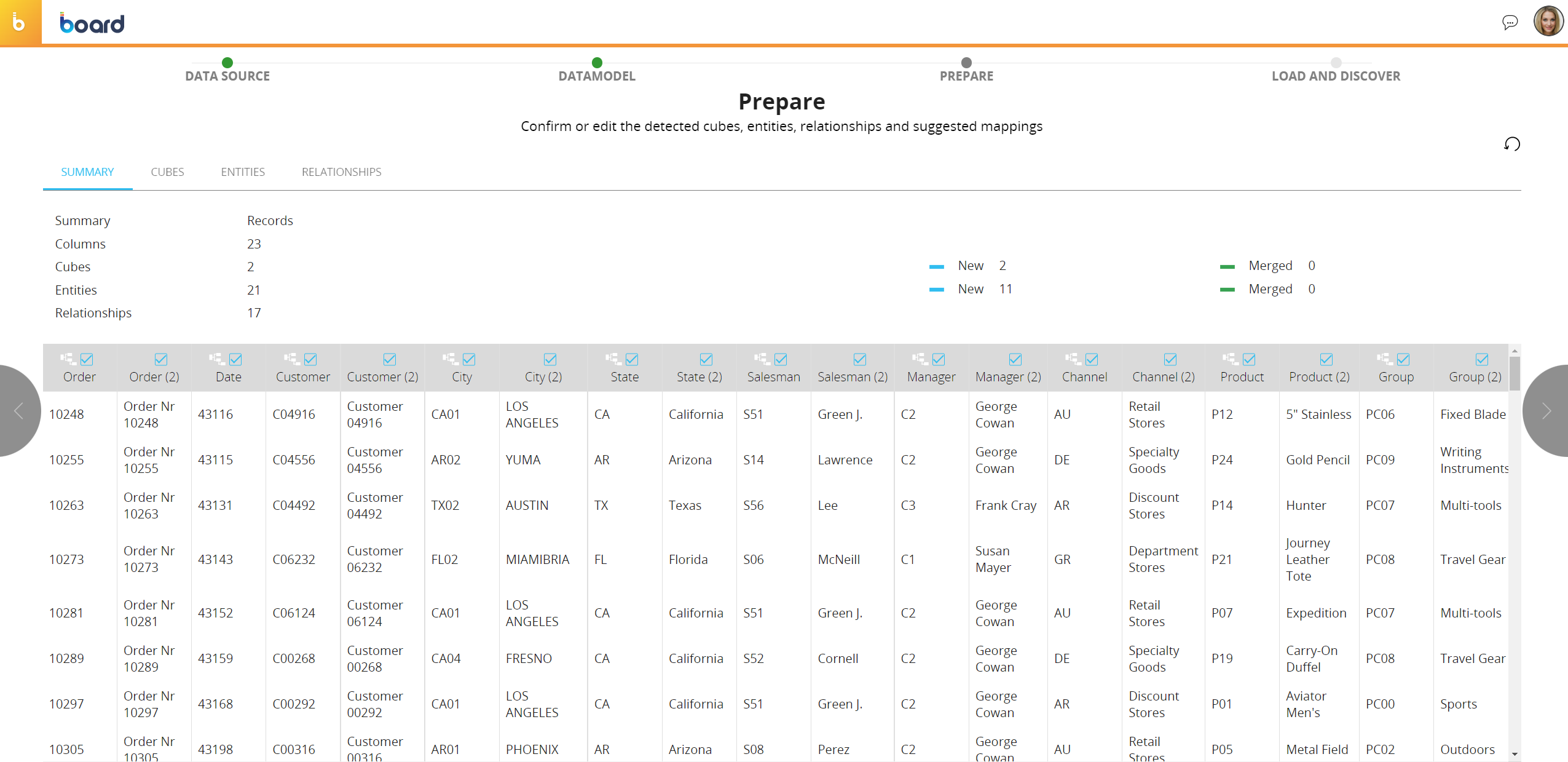 パネル上部のタブメニューから、検出されたすべてのキューブ、エンティティ、または関係が一覧表示される追加テーブルにアクセスできます。関係テーブルの対応するチェックボックスをオフにすることで、提案された関係を破棄することができます。
パネル上部のタブメニューから、検出されたすべてのキューブ、エンティティ、または関係が一覧表示される追加テーブルにアクセスできます。関係テーブルの対応するチェックボックスをオフにすることで、提案された関係を破棄することができます。
下の表では、列見出しのチェックボックスをオンまたはオフにして、対応する列を破棄することができます。
いずれかの列ヘッダーをクリックすると、ポップアップウィンドウでエンティティまたはキューブの以下の属性を編集することができます。
既存のエンティティやキューブの認識は、カラム名を使用して行われるため、マッピングが正しく行われるためには、Board内の既存のオブジェクトの名前と一致する必要があります。対応関係が正しく検出されると、エンティティやキューブは[新規(New)]ではなく[マージ(Merged)]として認識されます。-
名前(Name):作成されるエンティティまたはキューブの名前
-
タイプ(Type):作成される列の性質(エンティティコード、エンティティの説明、キューブ、時間軸、Null)
-
マップ先(Mapped to):元のカラム名
-
適合%(% of Match):データソース項目と作成されるエンティティ間の一致率(該当する場合)
-
親(Parent Of):作成される関係の階層的な依存関係の提案
-
子(Child Of):作成される関係の階層的な依存関係の提案
-
-
ステップ4 - ロードとディスカバリー(LOAD AND DISCOVER) データファーストトラックツールは、Boardデータモデルを作成/編集しデータをロードするための準備が整いました。
先に進む前に、利用可能なオプションの中から適切なものを選択することができます。-
データの読み込みと置換(Load and replace data):このアクションは、データをロードし、キューブの既存のデータを置き換えます。
-
ビッグデータ(BigData):可能な場合、ビッグデータ用のキューブ構造が適用されます(非推奨)。
-