データブロック設定について
データブロックをクリックすると、右側のスライドパネルにあるブロック設定から、追加設定とプロパティを構成できます。
[ブロック設定(Block settings)]パネルには、設定中のレイアウトに関連付けられた画面オブジェクトでデータとその外観を操作するためのオプションが豊富にあります。 設定には、すべての画面オブジェクトに共通するものと、個別の画面オブジェクトに固有のものがあります。
個別のオブジェクトに固有の設定については、本マニュアルでそれらについて記載したセクションとページを参照してください。
すべての画面オブジェクトに共通するブロック設定
設定には、特定のブロックに適用できない場合のものや、特定の画面オブジェクトに適用できないものがあります。 この場合、システムが設定エラーを検出しだい、レイアウトエディタの右下隅に[問題を解決(SOLVE ISSUES)]ボタンが表示されます。このボタンをクリックすると、不正なブロック設定に関する詳細情報が表示されます。
次のブロック設定は、設定中のレイアウトに関連付けられた画面オブジェクトに関係なく、常に利用可能です。
見出し
[見出し(Heading)]フィールドでは、データブロックのカスタム列見出し名を設定できます。 省略した場合、列見出し名には、データブロック一覧に表示されているキューブ名、エンティティ名、アルゴリズム式、ルール名、ランキング関数名が反映されます。
画面オブジェクトのタイプによっては、見出しが表示されない場合があります。
ブロック一覧に追加されたデータタイプによっては、[見出し(Heading)]メニューは追加設定ができます。たとえば、アルゴリズムの見出しの下には、アルゴリズムタイプドロップダウンメニューに加え、実際の式が表示されます。
表示
[表示(View)]メニューは、デフォルトで展開され、以下の設定が可能です。
- [数字(Digits)]。表示する小数点以下の桁数を設定します。このオプションは数値にのみ適用されます。
- [サマリー(Summary)]。 行と列の合計を計算する方法を定義します。
キューブ付きブロックの場合、オプションは次のとおりです。- [合計(Total)]。合計は、値を加算することで計算されます
- [合計なし(No total)]: 合計が無効になっているため、列と行の合計セルが空白になっています
- [平均(Average)]。 列の値の平均を返します
- [最大値(Maximum value)]。列の最大値を返します
- [最小値(Minimum value)]。列の最小値を返します
- [カウント(Count)]。列のエントリ数を返します
- [標準偏差(Standard deviation)]。列の値の標準偏差を返します。
アルゴリズム、ルール、ランキング関数を持つブロックには、以下のオプションがあります。
- [合計(Total)]。合計は、値を加算することで計算されます
- [計算済み(Calculated)]。式は、行と列の合計に再適用されます。 このオプションは、たとえばパーセンテージを計算するアルゴリズムや、除算を含むその他の式で選択する必要があります。
- [除算(Divide by)]。 値を指定された数値で除算します。 このオプションは、値を千または百万単位で表示できます。
このオプションは、数値キューブを持つブロックにのみ適用できます。
- [ツールチップ(Tooltip by)]。 レイアウトの他のブロックの内容に基づいた情報(数値、テキスト、画像、添付ファイルなど)を表示します。
[ツールチップ(Tooltip by)]機能は、BLOBキューブと合わせて使用すると特に便利です。コメント、画像、Excelファイル、その他のあらゆる添付ファイルをレポートの任意のセル(見出しを除く)に「リンク」できるためです。[ツールチップ(Tooltip)]オプションは、BLOB CUBEを含む、レイアウトの任意のブロックを参照できます。 この場合、データエントリは、参照されるBLOBキューブでも有効にできます。
- [ブロックを非表示(Hide block)]。 有効にすると、対応するブロックが非表示になります
- [行の合計(Row totals)]。行の合計の計算を有効または無効にします。 このオプションは、レイアウトに少なくとも1つのエンティティが列で設定されている場合にのみ適用されます。
- [ゼロを非表示(Hide zeroes)]。有効にすると、ゼロ値(0)を含むセルは空白として表示されます。
カラーアラート
カラーアラート設定では、データブロックに条件付きフォーマット(警告)を設定できます。 フォーマットオプションは、アラート設定に基づいて、選択された画面オブジェクトの値の外観を変更することもできます。
アラートはしきい値によって定義されます。設定はデフォルトで3つの色範囲(赤、白、緑)を表示しますが、必要なだけ範囲を追加できます。 色も自由にカスタマイズできます。
デフォルト設定では、赤カラーアラートしきい値より小さい値を含むブロックのセルは赤に、緑カラーアラートしきい値より大きい値を含むブロックは緑色になります。 赤の警告しきい値より大きく、緑の警告しきい値より小さい値を含むブロックのセルは、白で表示されます。
警告は、手動で入力したしきい値の値、またはレイアウト内の他のデータブロックの値に基づいて設定できます。 カラーアラートオプションが機能するためには、数値データ(キューブ、アルゴリズム、ランキング関数、ルール)を参照する必要があります。
次の4つの警告形式から選択できます。
- 数字(デフォルト)。 条件付きフォーマットが文字色に適用されます
- ブロック。条件付きフォーマットがセルの背景に適用されます
- ブロックのみ。条件付きフォーマットがセルの背景に適用され、値が非表示になります
- スマーティーズ。条件付きフォーマットは、セル自体で値の左側に表示される小さな円に適用されます。

データエントリ
データエントリオプションは、選択したデータブロックにデータエントリを行えます。 デフォルトでは、データエントリアクションを受け付けるセルは、象牙色の背景で表示されます。
次のものが入力されたブロックに対して、データエントリを有効にできます。
- キューブ。この場合、データエントリアクションによって、指定されたキューブに値(数値、テキスト、日付)またはファイルが保存されます。
BLOBキューブに対するデータエントリアクションは、物理レベルで実行する必要があります。つまり、軸領域の[行(BY ROW)]または[列(BY COLUMN)]フィールドにキューブ次元が存在する必要があります。
- アルゴリズム。この場合、データエントリアクションは、計算されたブロックの式を逆にして、値をキューブに保存します(後述の「逆アルゴリズム」の項を参照してください)
- エンティティ。この場合、データエントリアクションによって、階層関係を割り当てたり、変更したりできます
このオプションを有効にするだけでは、データエントリは有効になりません。 さらに以下の条件を満たす必要があります。
- ユーザーは、適切なBoardライセンスと、書き戻しアクションを実行するために必要なセキュリティ権限を持っている必要があります。
- テキスト、日付、およびBLOBキューブデータエントリは、物理レベルでのみ対応しており、集約表示では対応していません。
- データエントリオプションが有効な場合、時間機能(前年、年間累積値など)および参照機能(参照先、詳細など)を有効にすることはできません。
- レイアウト表示がデータエントリキューブの集約表示である場合、Data Split&Splat(論理データエントリ)機能が有効である必要があります。
データエントリと合わせて、同じデータブロック上で次のオプションを有効にすることが可能です。
- [Split splat](デフォルトでは有効):Data Split&Splat(論理データエントリ)機能を有効または無効にします
- [逆アルゴリズム(Reverse algorithm)]:計算されたブロック(アルゴリズム)に値を入力して、式の因子の1つを再計算して、対応するブロックに書き込むことができます。
例
次の例を考えてみましょう

データブロック"a"には予算額キューブが含まれ、データエントリオプションが有効になっているため、ユーザーはこのブロックに予算値を入力できます。
データブロック"b"(前年度の売上高実績)は、前年度の売上高を含んでおり、ユーザーが予算を決定する上で役立つ参照値である。
データブロック"c"は、式を使用したアルゴリズムで得られる差異率であり、式はc=(a-b)/b*100です。 データエントリオプションはこのデータブロックで有効になっており、ユーザーは任意の差異率を入力でき、Boardは与えられた差異に対応する予算額を導出できます。
予算額値は、[逆アルゴリズム(Reverse algorithm)]フィールドで逆式(a=b*(c+100)/100)を適用して導出される。
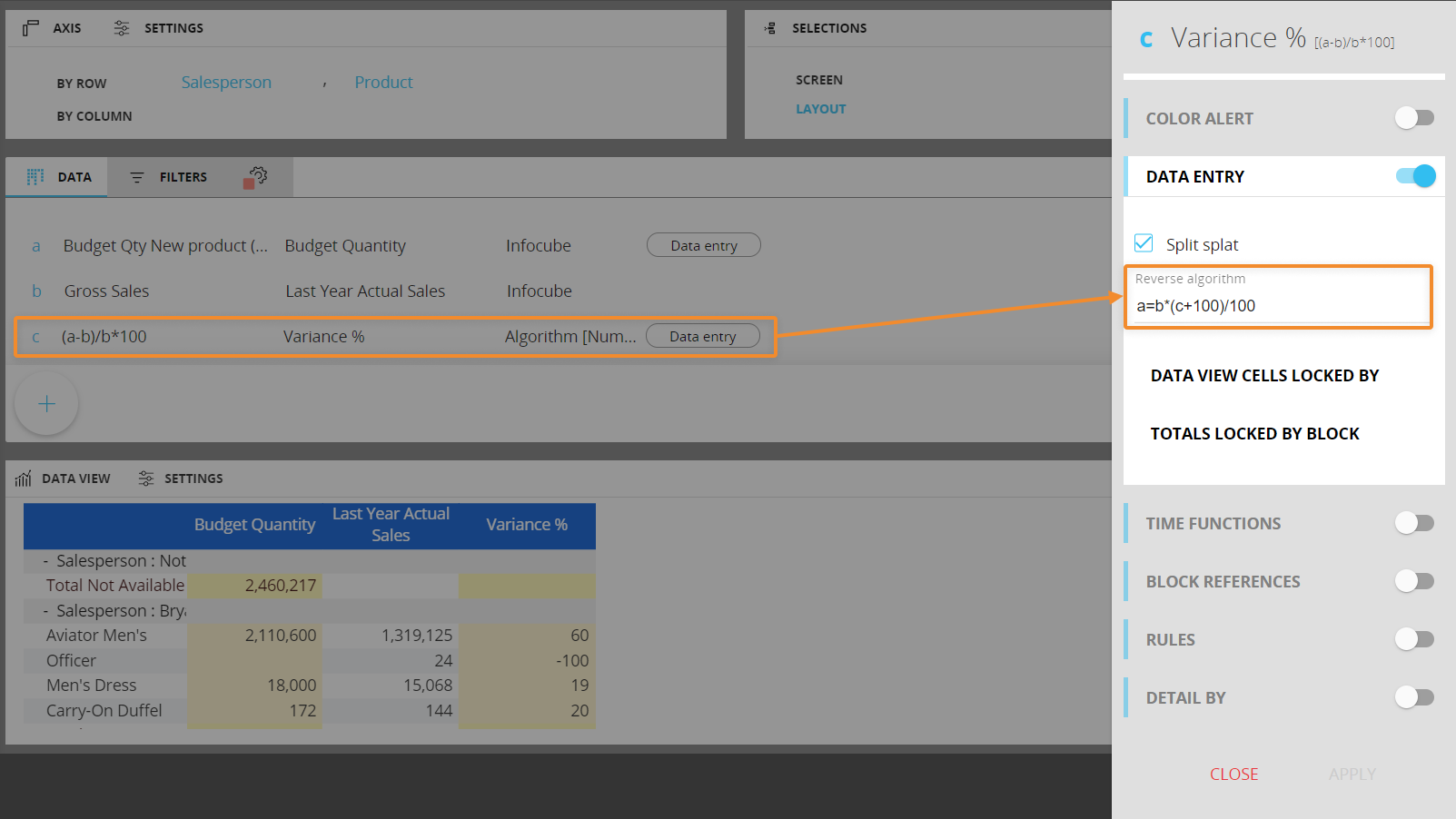
逆アルゴリズムフィールドには、以下の順序で必要な要素を入力します。
-
ユーザーが値を入力したときに変化する変数を表すデータブロック(上記の例ではブロック"a")
-
等号
-
式そのもの(上記の例ではa=b*(c+100)/100 )
逆アルゴリズムのターゲットデータブロックは、データエントリオプションが有効なキューブである必要があります。
-
- 検証ルール:入力した値を自動的に受け入れまたは拒否するための検証式を定義できます。
これにより、たとえば入力値が正である場合(予算価格の場合)、または入力値が与えられた値または他のデータブロックの値よりも小さいか大きい場合のみ、入力値を受け入れることができる。
検証ルールは、入力された値の条件がTRUEかFALSEかをチェックする論理式です。式がTRUEを返した場合、ルールは満たされ、入力された値は受け入れられます。式がFALSEを返した場合、入力された値は受け入れられず、カスタムメッセージとともにエラーアイコンが表示されます

検証ルールは、[データエントリ(Data entry)]メニューで定義されます。[入力検証ルール(Input validation rules)]をクリックし、[新規ルール追加(Add new rule)]をクリックして、論理式と、ルールに合致しない場合に表示する対応エラーメッセージを入力します。

論理式はアルゴリズムと同じ構文を使用します。
[変更された値のみを検証(Validate only changed values)]オプションは、変更されたセルにのみ検証ルールを適用します。 これは、既存のレイアウトに検証ルールを追加した結果、新しいルールを満たさないが、表示する必要がある値(たとえば、履歴データなど)が発生した場合に特に便利です。 - 推奨値。データエントリアクション(修正するセルをダブルクリックする)中にユーザーに表示される推奨値を設定できます。 これらの値は、レイアウト内の他のブロックまたはエンティティ、あるいは手動で設定されたカスタム一覧から取得されます。
例
ブロック"a"(「予算額」)において、データエントリと推奨値のオプションが有効になっています。 ブロック"b"(「販売数量」)は、ユーザーに推奨する値を含んでいます。
レイアウトエディタでの設定は以下の通りです。

この設定をDataViewで行った結果は以下の通りです。

エンティティまたはカスタム一覧から取得した推奨値がある場合、ユーザーには1つのデータエントリアクションに対して複数の推奨値を表示されます。 一覧は縦スクロールに対応しており、ユーザーがセルに書き込むとその要素がフィルタされます。
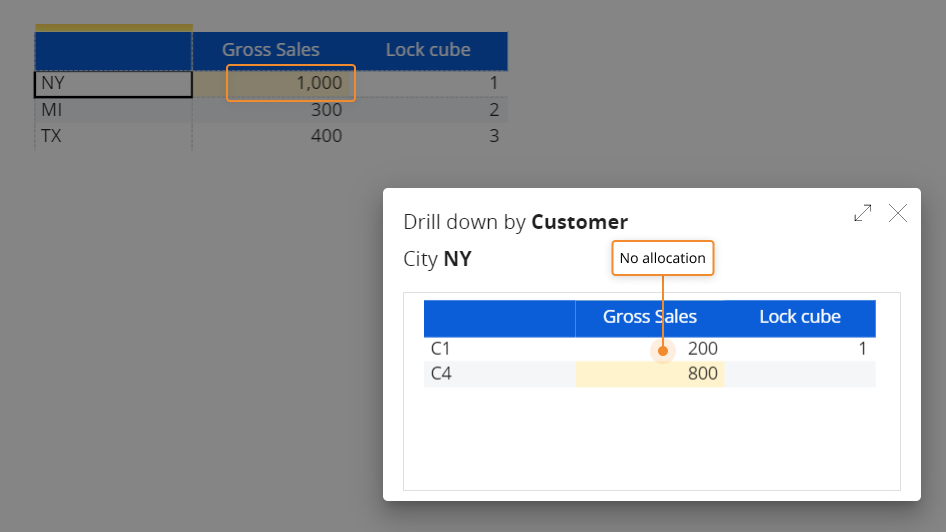
- パターンに基づく割り当て。 論理データエントリは、Data Split&Splatとも呼ばれ、任意の集約レベルで数値データを入力し、Boardが自動的にキューブの下位セルにまで割り当てできる機能です。
パターンに基づく割り当てオプションをオンにすると、選択されたキューブにユーザーが合計値を入力すると、データエントリアクションを行ったキューブとは別のキューブから取得したパターンに基づいて、その合計に寄与する詳細セルまで自動的に割り当てる機能です。
割り当ては、製品、顧客、地域、時間など、キューブのあらゆる次元で、階層の最も詳細なレベルまで行われます。データエントリが有効になっているキューブと、データエントリパターンを提供するキューブは、同じ構造を共有する必要があります。 この機能によって、比例以外のパターン(ドライバー)を使用してデータを割り当てることができます。
パターンに基づく割り当てが有効な場合、設定されたキューブで実行される各データエントリアクションで、そのパターンを使用するようユーザーに要求されます。 ユーザーが使用しないことを選択した場合、従来のSplit&Splatによる割り当てが行われます。
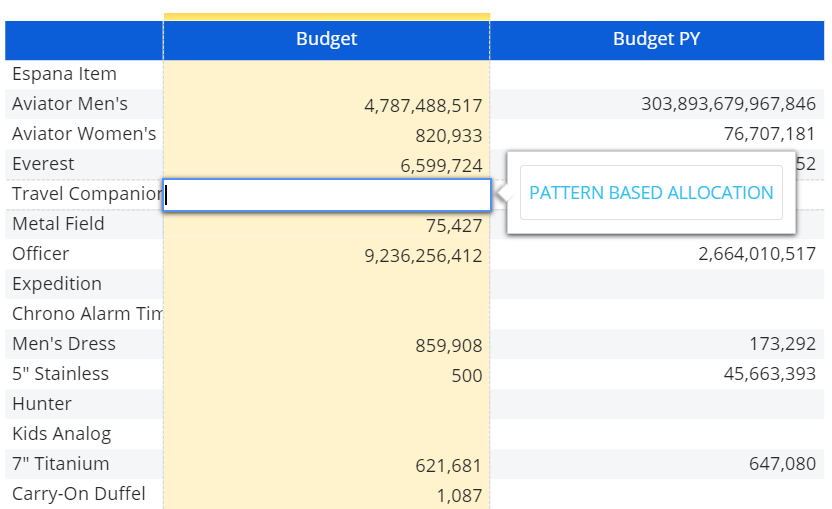
レイアウトエディタでの設定は以下の通りです。

パターンに基づく割り当てにより、空のセルにも集約レベルでデータを挿入できます。 割り当てを検証するには、データエントリアクションを行ったセルで集約度の低い次元にドリルダウンし、入力した値が下位のセル間でどのように分割されたかを確認します。
パターンに基づく割り当ては、「データエントリ」アクショングループの「パターンに基づく割り当てを使用したデータエントリの保存」という名前のプロシージャとしても利用できます。 - [DataViewセルをロック(Data View cells locked by)]。DataViewにおいて、このオプションによって、他のブロックからの値に基づいて、セルへのデータエントリをロックまたはロック解除できます。ロックされたセルは、異なる背景色で表示されます。
ロックルールはDataViewに表示されるデータ集約レベルで動作するため、画面上に表示されているセルのみを考慮します。 別の集約レベルにドリルダウンした場合、ロックルールはドリルダウンウィンドウに表示されているセルだけを考慮します。ロックブロックの値がゼロに等しい(または設定によってはゼロに等しくない)場合、現在のブロックでデータエントリアクションが許可されます。 ロックブロックの他の値については、データエントリオプションがアクティブな場合であっても、データエントリアクションが無効になります。
たとえば、次のDataViewで、「DataViewセルをロック」ルールが総売上高ブロックに設定されている場合を考えてみましょう。
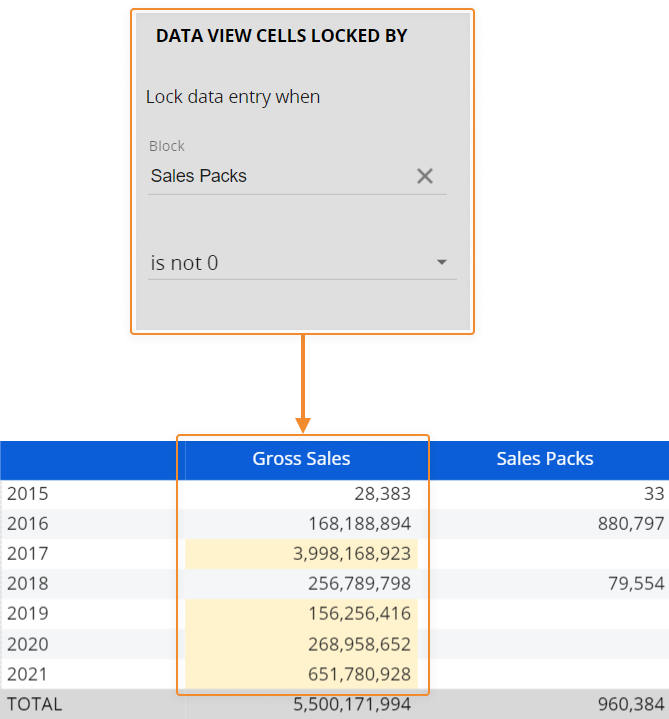
DataViewでロックされている2018年に対応するセルを月単位でドリルダウンした場合であっても、ロックルールはドリルダウンウィンドウに表示されているセル(現在の集約レベルのセル)のみを考慮するため、キューブにデータを入力することは可能です。

- [ブロックごとの合計ロック(Totals locked by Block)]。 単一ブロックの行合計または列合計で条件付きロックを適用します。 このオプションを有効にすると、データエントリのたびに、合計が固定(ロック)された合計である詳細セルに比例再割り当てが行われます。
合計がロックされると、セルに小さなロックアイコンが表示されます。
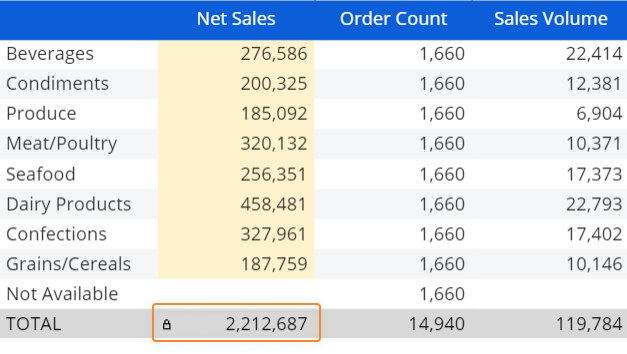
ロックブロックの値がゼロに等しい(または設定によってはゼロに等しくない)場合、行合計セルまたは列合計セルで現在選択されているブロックでデータエントリアクションが許可されます。 ロックブロックの他の値については、データエントリオプションがアクティブな場合であっても、行合計セルまたは列合計セルでデータエントリアクションが無効になります。
- [ロックされたキューブセル(Cube cells locked by)]。このオプションによって、他のキューブからの値に基づいて特定のキューブの物理セルへのデータエントリをロックまたはロック解除し、ロックされたセルを表示または非表示にできます。ロックされたセルは、異なる背景色で表示されます。
ロックされたキューブセルルールは、DataViewに実際に表示されるセルに関係なく、あらゆるレベルの集約にわたってキューブレベルで機能します。少なくとも1つの下位セルで割り当てが許可されていれば(かつそのセルの値が0でなければ)、常にデータエントリアクションを実行できます。
[表示(Display)]ドロップダウンメニューでは、フリー(編集可能な)セルの値のみを表示するか、フリー&ロックされたセルの両方の値を表示するかを設定できます。[フリーセルのみ(Free cells only)]オプションを選択すると、集約表示ではキューブの物理レベルでロックされていないセルだけが考慮されます。ロックキューブの値がゼロに等しい(または設定によってはゼロに等しくない)場合、現在のキューブでデータエントリアクションが許可されます。 ロックキューブの他の値については、データエントリオプションがアクティブな場合であっても、データエントリアクションが無効になります。
たとえば、次のレイアウトで、総売上高ブロックにロックされたキューブセルルールが設定されている場合を考えてみましょう。
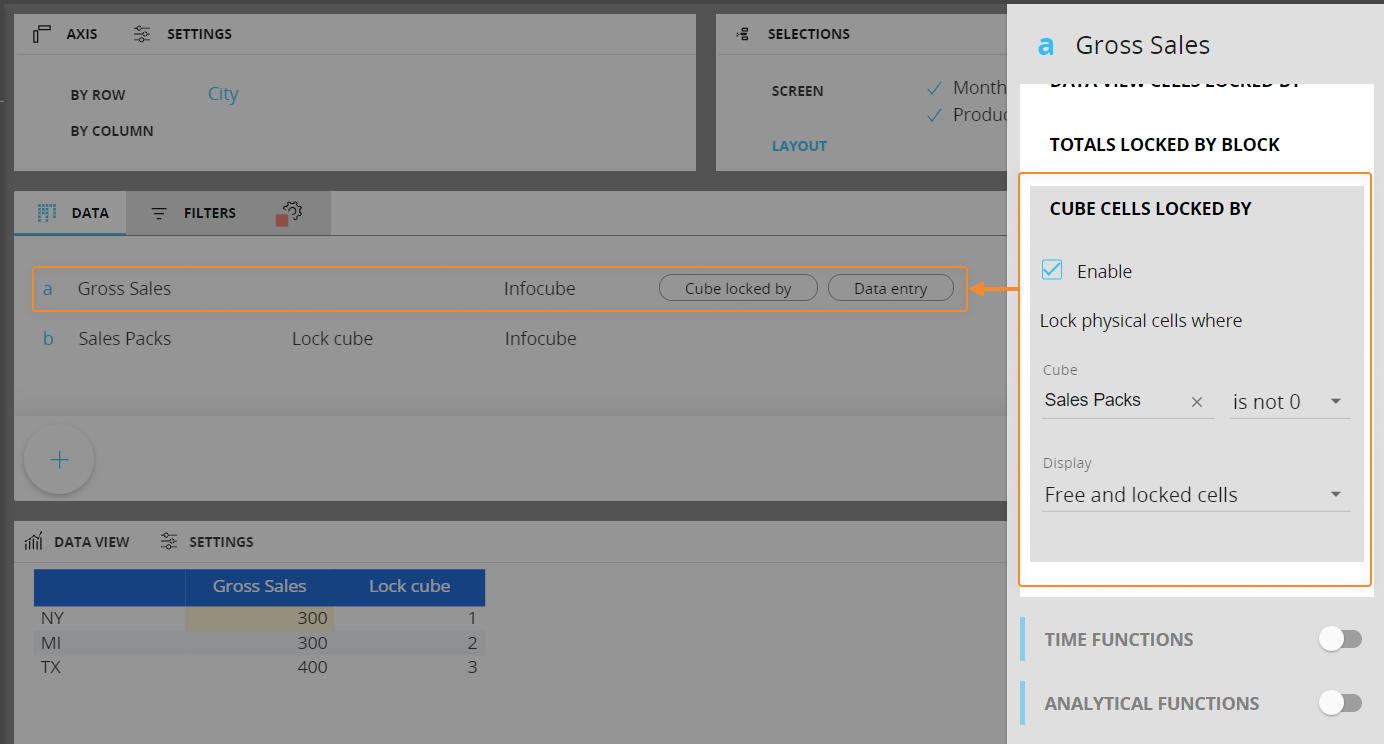 結果として得られるDataViewの最初の行で顧客別にドリルダウンすると、1つの下位セルがロックルールに従ってロックされ、もう1つはフリー(編集可能)となります。
結果として得られるDataViewの最初の行で顧客別にドリルダウンすると、1つの下位セルがロックルールに従ってロックされ、もう1つはフリー(編集可能)となります。
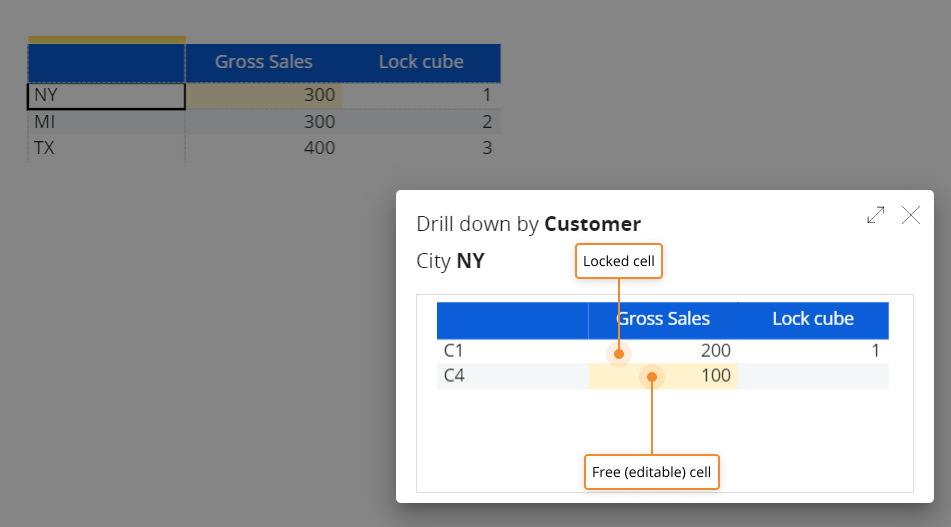
DataViewでNYの総売上高の値を変更して再度ドリルダウンすると、フリーセルにのみ異なる値が表示されます。ロックルールにより、Split&Splat機能でキューブのロックされた下位セルに新しい値が割り当てられないようになります。
時間関数
時間関数により、前年比データを比較する分析の作成、年初来データ、予測データ、ローリング合計の取得などを手早く実行できます。 一般的に、時間関数は、数値キューブを含むデータブロックに適用されます。
時間関数は、1次元しかないキューブや、カスタム時間エンティティで構造化されたキューブには適用できません。
利用可能な時間関数は以下の通りです。
- [前年(Previous Year)]。 チェックボックスがオンであり、他の機能またはオプションがアクティブではない場合、現在選択されている期間の前年のデータを返します。 たとえば、現在の画面選択が2021年5月から2021年7月の場合、前年機能では2020年5月から2020年7月のデータが返されます
- [機能(Function)]ドロップダウンメニュー:
- [値(Value)](デフォルト)。 関数を適用しません
- [前の期間の値(Previous Period Value)]。 現在選択されている期間に基づき、以前の期間のデータを返します。 たとえば、月エンティティで現在の選択が2021年7月と2021年8月であれば、2021年6月と2021年7月のデータを返します。 週エンティティの現在の選択が15週目である場合、この関数は14週目のデータを返します。
- [前年値(Previous Year Value)]。 一覧の冒頭で述べた[前年(Previous Year)]チェックボックスと全く同じ働きをします。現在選択されている期間について、前年のデータを返します
- [年間累積値(Yearly Cumulated Value)]。 年初来の累積値を返します。 たとえば、月で次元化されたキューブにこの関数を適用すると、現在選択されている年の1月からの累積値が返されます。日で次元化されたキューブに適用すると、現在選択されている年の初日からの累積値が返されます。
年間累積値機能は、[会計年度(Fiscal Year)]オプション(チェックボックス)と組み合わせることで、現在選択されている会計年度の最初の期間からの累積値を得ることができます。 このオプションは、使用中のBoardデータモデルの[時間範囲(Time range)]セクションで会計年度が設定されている場合にのみ利用可能です。
[サイクル(Cycle)]フィールドを使用して、累積値計算のための異なるローリング期間を設定できます。 たとえば、月で次元化されたキューブでサイクルを「2」に設定すると、現在選択されている年の2年前の1月から当月までの累積値が得られます。
累積時間関数の計算は、キューブ構造の時間次元ではなく、レイアウトエディタの軸領域に追加された時間次元によって行われます(つまり、月ごとのレイアウトで週で次元化されたキューブに、年間累積値などの累積時間関数を適用できます)。
[年間累積値(Yearly Cumulated Value)]関数を使用するには、レイアウトの軸領域に同じ時間エンティティで次元化された特定のキューブバージョンを作成する必要はありません。 - [年間移動合計(Yearly Moving Total)]。 現在選択されている期間までの過去12か月間の累積値を返します。 これはローリング年間合計であるため、新しい月のデータが合計に加えられ、期間の最初の月のデータが除かれ、毎月末に変化します。たとえば、現在の選択が月エンティティで2021年7月である場合、関数は2020年8月から2021年7月までの累積値を返します。
[サイクル(Cycle)]フィールドを使用して、異なるローリング期間を設定できます。 サイクル値は、計算で考慮する期間の数を定義します。 たとえば、月で次元化されたキューブでサイクルを"3"に設定すると3か月のローリング合計になり、サイクルを"6"に設定すると6か月のローリング合計になります。 日で次元化されたキューブでサイクルを90に設定すると、過去90日間のローリング合計が得られます。
- [年間移動平均(Yearly Moving Average)]。 現在選択されている期間までの過去12か月間の平均期間値を返します。 たとえば、月で次元化されたキューブに適用すると、この関数は年間移動合計値を12で除算した値を返します。
[サイクル(Cycle)]フィールドを使用して、平均値計算のための異なるローリング期間を設定できます。たとえば、月で次元化されたキューブでサイクルを"3"に設定すると3で除算された3か月のローリング合計になり、サイクルを"6"に設定すると6で除算された6か月のローリング合計になります。
- [最後の値(Last Value)]。 この関数は、時系列で最後に見つかった非ゼロ値を、新しい非ゼロ値が出てくるまで後続のゼロ値セルに複製した後、新しい値を後続のゼロ値セルに複製します。たとえば、月ごとのレイアウトで現在の選択が2020年7月から2021年7月までであり、2020年12月までのデータがある場合、この関数は2020年12月の値を2021年1月、2021年2月、2021年3月、2021年4月、2021年5月、2021年6月、2021年7月に複製します。
- [トレンド(Trend)]。 キューブに一次関数を適用し、将来の期間の予測値を計算します(チャート上にプロットすると、予測が直線で表現されます)。 トレンド関数の計算に使用される統計モデルは、移動平均モデルに基づいています。
トレンド機能は、少なくとも1年分の履歴データを持つキューブに適用することを推奨します。
トレンド関数を[現在の期間を無視(Ignore Current Period)]オプション(チェックボックス)と組み合わせると、統計関数の計算に使用されるデータセットから、現在の時間選択の最後の期間を除外できます。 - [予測(Forecast)]。 キューブに統計的予測機能を適用し、将来の期間の予測値を計算します。 この関数は、キューブの履歴データからトレンド成分と季節成分を推定し、過去のトレンドと季節性を含んだ予測を返します。
Boardは、利用可能な履歴データシリーズに応じて、指数平滑化および移動平均モデル、ARIMAモデル、Wintersモデルに基づく3つのオプションから最適な統計モデルを自動的に選択します。予測関数を[現在の期間を無視(Ignore Current Period)]オプション(チェックボックス)と組み合わせると、統計関数の計算に使用されるデータセットから、現在の時間選択の最後の期間を除外できます。[現在の期間を無視(Ignore Current Period)]。 このオプションは、[トレンド(Trend)]または[予測(Forecast)]統計関数を使用する場合に有効にできます。 統計関数の計算に使用されるデータセットから、現在の時間選択の最後の期間を除外します。
- [期間オフセット(Period Offset)]。 指定された期間数分、時間選択をシフトします。 たとえば、期間オフセットを"-3"に設定すると、現在選択されている期間の3つ前の期間の時間選択に対してこの関数が適用されます。キューブ構造に応じて、3か月、3週、3日になります。 月で次元化されたキューブに"-12"の期間オフセットを適用すると、[前年(previous Year)]関数と同等の結果が得られます。
[期間オフセット(Period offset)]オプションは、[前年(Previous Year)]オプションと併用できません。
-
[サイクル(Cycle)]。 以下の累積関数の期間を定義します。
-
年間累積値
-
年間移動合計
-
年間移動平均
-
ブロック参照
[ブロック参照(Block references)]メニューでは、キューブを持つデータブロックに[参照先(Refer to)]関数を適用して、その集約または詳細レベル
[参照先(Refer to)]関数によって、データブロックは画面選択(選択)と軸設定を無視して、特定のエンティティの発生を参照できます。
そのためには、[参照を追加(ADD REFER TO)]ボタンをクリックし、ポップアップウィンドウからエンティティを選択し、必要なエンティティメンバーを選択します。
例
州エンティティの「カリフォルニア」メンバーに「参照先」条件を設定すると、この関数は、以下のように行、列、選択設定にかかわらず、その州のデータを返します。

レイアウトエディタでの設定は以下の通りです。
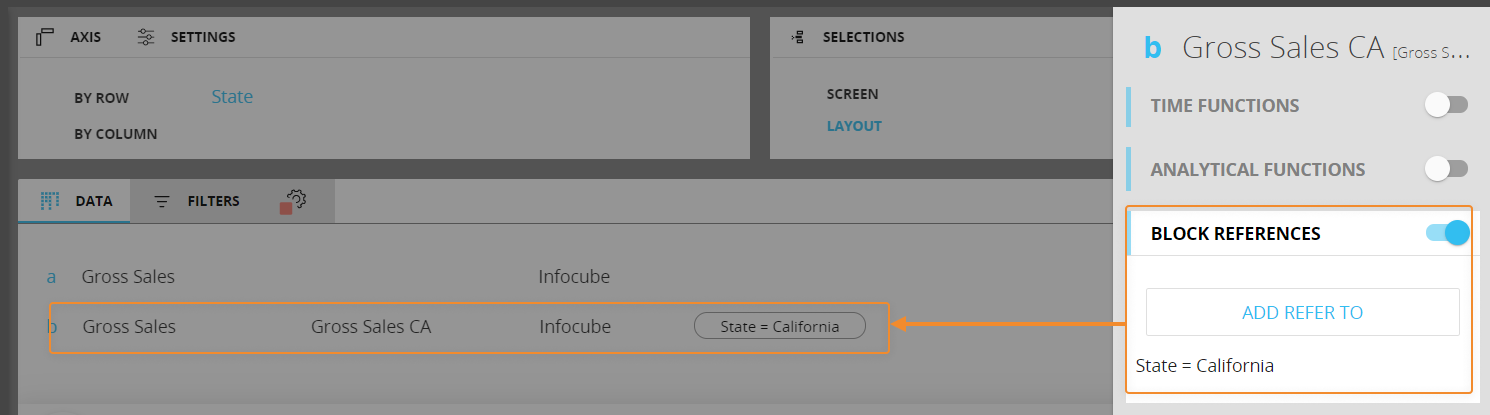
お互いに制限をかけない限り、データブロックに設定できる「参照先」条件の数に制限はありません。たとえば、国エンティティの「イタリア」メンバーに「参照先」条件を設定し、都市エンティティの「サンフランシスコ」メンバーに別の条件を設定すると、結果として空のセルが得られます。
[参照先(Refer to)]関数は、合計を得るためにも使用できます。行または列で設定されたエンティティよりも集約されたエンティティに対して「参照先」条件を設定すると、この関数は参照された出現頻度値を返します。 たとえば、月エンティティと都市エンティティがそれぞれ列と行で設定されているレイアウトで年エンティティと州エンティティに「参照先」条件を設定すると、この関数はすべてのセルで参照される年と州の合計値を返します。
例

レイアウトエディタでの設定は以下の通りです。

ルール
[ルール(Rules)]メニューでは、データブロックにルールを適用できます。 このメニューから選択されたルールは、データパネルからレイアウトエディタのデータ領域にルールをドラッグアンドドロップした場合とは逆に、選択されたデータブロックに一意に関連付けられます。
ルールを使用すると、同じエンティティの他のメンバーを含む式の結果として、特定のメンバーを定義できます。
ルールは常に1つのエンティティに関連付けられ、構造内の次元としてそのエンティティを持つキューブにのみ適用できます。
ルールは、関連するエンティティが行または列で設定されているレイアウトで使用する必要があります。 エンティティが行ごとに設定されている場合、グループ化エンティティとして同じフィールドに別のエンティティ(つまり、[行(BY ROW)]フィールドの一番左の位置にあるエンティティ)を追加できます。 これらのエンティティは、同じ階層にあってはなりません。
詳細はルールを参照してください。
[ルール(Rules)]メニューでは次のオプションを使用できます。
- [合計に適用(Apply on totals)]。 有効にすると、合計にもルールが適用されます。
- [ロールアップ(Rollup)]。 データブロックの自動ロールアップを有効にします。 ロールアップエンティティは、メンバーが階層符号化構造を持つエンティティです。 ロールアップエンティティがレポートで使用されると、Boardは自動的に「子」行の「親」である行の合計と小計を計算します(つまり、ある発生のコードは、より詳細なレベルにある他のメンバーのコードの始まりを表します)。
- [不規則階層を無効にする(Disable unbalanced hierarchy)]。 データブロックの不規則階層集約を無効にします
[詳細(Detail by)]
[詳細(Detail by)]オプションでは、すべての列のデータを表示するエンティティを選択できます。 このオプションは、レイアウトエディタの軸領域で定義された[列(By Column)]設定より優先されます。
また、[順序(Order)]メニューを使用して値を並べ替えることもできます。 次の設定を使用できます。
- [並び替えなし(Not sorted)](デフォルト)。 並び替えは適用されません
- [降順(Descending)]。 n個の列のみを考慮して、下から順に値を返します。nは、[最上部を維持(Keep top)]フィールドで定義される値です。
- [昇順(Ascending)]。n個の列のみを考慮して、上から順に関数の結果を返します。nは、[最上部を維持(Keep top)]フィールドで定義される値です。
例
次の例を考えてみましょう。

総売上高値は、チャンネル(列)および年(行)ごとに表示されます。
レイアウトエディタでのレポートの設定は以下の通りです。
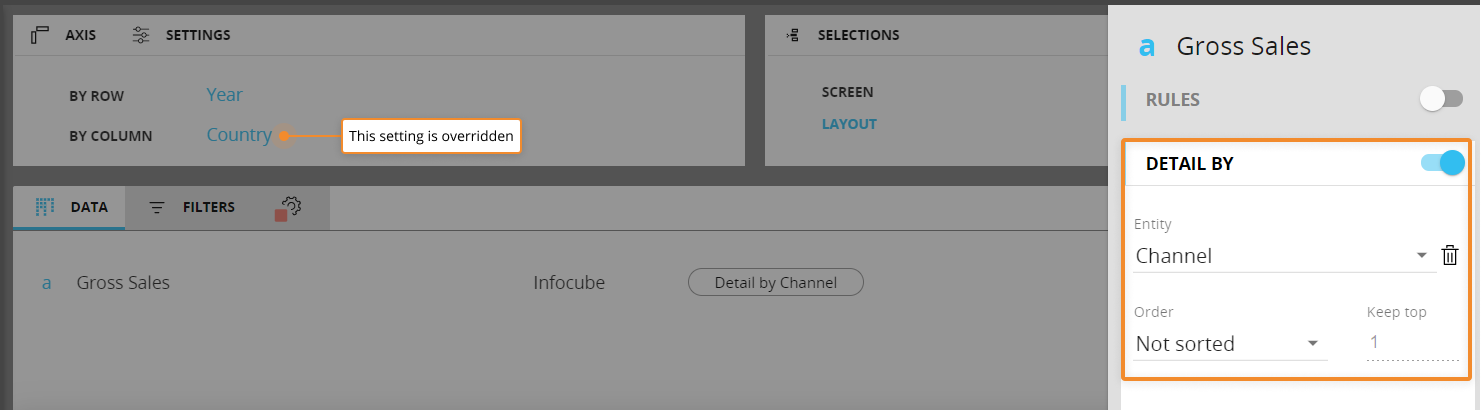
ご覧の通り、[列(BY COLUMN)]エンティティは[詳細(Detail by)]関数設定によって上書きされます。
[合計(Total by)]
[合計(Total by)]関数によって、軸領域のエンティティよりも高いレベルでキューブを集約できます。 この関数は、パーセンテージなどの指標の計算に特に便利です。
例
以下のレポートを考えてみましょう。
- 都市エンティティが行ごとで追加されました。
- 1列目は売上高値を示しています
- 2列目は、州エンティティに[合計(Total by)]関数を適用した売上高値を示しています。 この設定では、対応する都市が属す各州の売上高合計値を返します。
- 3列目は、各都市の総売上高が、それが属す州の売上高合計値に対して占めるパーセンテージを計算しています。

レイアウトエディタでの設定は以下の通りです。
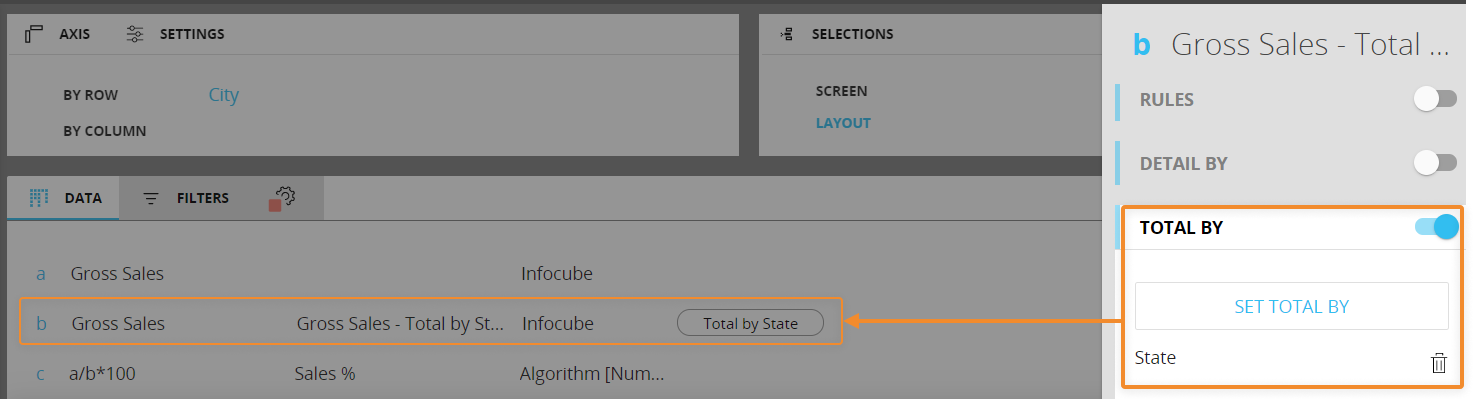
ご覧の通り、[合計(Total by)]関数により、ブロック"b"の値は、行ごとに設定されたエンティティ都市よりも高いレベルの集約で表示されるため、ブロック"c"のパーセンテージを簡単に計算できます。
集約
[集約(Aggregation)]メニューでは、データブロックに集約関数を適用できます。
利用可能な関数は以下の通りです。
- [合計(Sum)]。選択されたエンティティの合計を返します。たとえば、商品グループと月ごとに設定されたレポートにおいて、エンティティ商品の合計関数は、月ごとに詳細化された商品グループごとに販売された商品の合計を返します。
- [個別カウント(Distinct count)]。 各セルに含まれる選択されたエンティティの個別アイテムの数を返します。 たとえば、顧客と月ごとに設定されたレポートにおいて、エンティティ商品の個別カウント関数は、月ごとに詳細化された顧客ごとに販売された商品の個別の数を返します。
- [平均(Average)]。選択されたエンティティの平均を返します。ここでは、平均 = 合計/個別カウントとなります。
[限定(Limit to)]オプションを使用すると、この関数が考慮するエンティティメンバーを絞り込むことができます。
- [なし(None)](デフォルト)。 フィルタを適用しません
- [最上位(Top)]。 n個のエンティティメンバーのみを考慮して、上から順に関数の結果を返します。nは、[アイテム数(Item count)]フィールドで定義される値です。
- [最下位(Bottom)]。n個のエンティティメンバーのみを考慮して、下から順に関数の結果を返します。nは、[アイテム数(Item count)]フィールドで定義される値です。
- [範囲(Range)]。[From]および[To]フィールドで定義されたエンティティメンバーの範囲から関数の結果を返します。
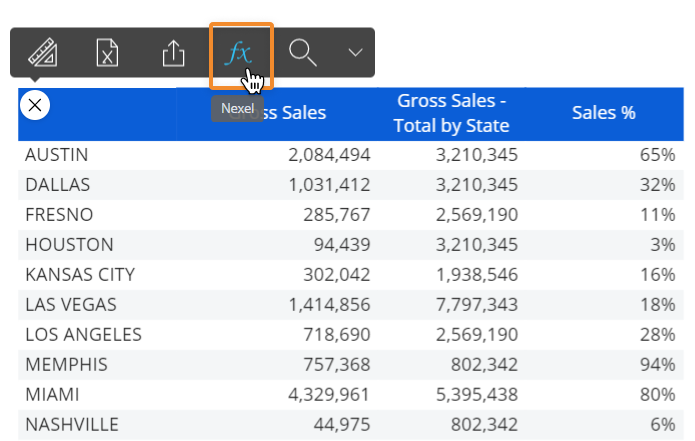
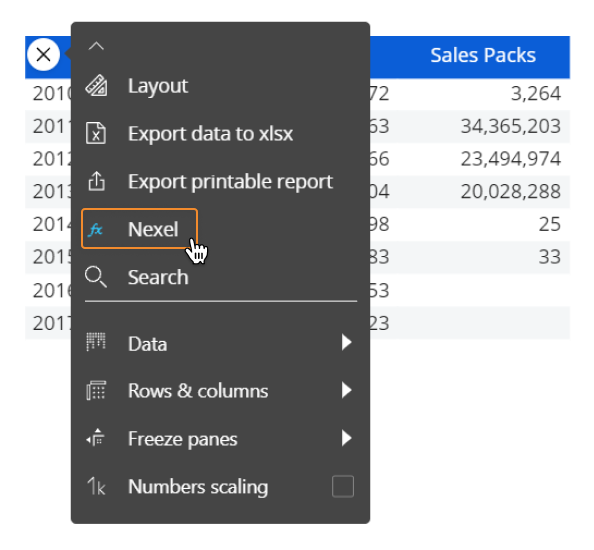
Nexel
Nexelは、スプレッドシートのようなアプリケーションの柔軟性と汎用性を、DataViewとしての多次元オブジェクトの機能と堅牢性と組み合わせています。 レポートレイヤーに埋め込まれた式の幅広いライブラリを提供し、列、セルの範囲、さらには単一のセルに関する追加の計算機能を提供します。
Nexel式は、計算、情報の取得、セルの内容の操作、テスト条件などを実行できる数式です。 式は常に等号(=)で始まり、次を含むデータブロックでサポートされます。
- キューブ
- アルゴリズム
- エンティティと関係
Nexel式の結果は、レイアウト定義で生成された値と重複します。
ブロック設定パネルの[Nexel]メニューで、選択したブロックのNEXELレイヤーを有効にして設定できます。 有効にすると、ブロックのセルに式を伝播する方法を定義することもできます。 次の2つのオプションを使用できます。
- [最深エンティティの式(Deepest entity formula)](デフォルト)。ブロックの各セルには、異なる式を指定できます。
- [単一の式(Single formula)]。 式はブロックのすべてのセルで同じです
有効にすると、DataViewのスライドツールバーから設定できます。