SQL FastTrackはバージョン8より利用可能になった強力かつ先進のBoard機能です。1つ以上のSQLソースからデータ及びメタデータを取り出し、Boardデータベースを自動的に作成し、フィードすることが出来ます。FastTrackは1回のクリックで、リレーショナルデータセットを読み込み、自動的にそれを分析し、データ内での関係を検出し、多次元Boardデータモデルを生成し、それを投入します。
一目似ているように見える2つの道具の違いを明確に示すことが重要です。
SQLデータリーダーは既存のデータベースをフィードすることが出来ます。つまり、SQLデータリーダーを使用する場合、ロードする前にエンティティ、関係、及びキューブを定義する必要があります。一方、FastTrackは新しいBoardデータベースでも動作出来、必要なすべてを自動的に作成します。
手短に言うと、FastTrackはまずエンティティ、関係、及びキューブを作成し、それらをフィードするためにデータリーダーを作成し、実行します。
FastTrackの使用方法を見て行きましょう。
FasTrackを使用する前に、新しいデータベースを作成し、Boardクライアントの[データベースマネージャ(DatabaseManager)]タブに移動し、SQL FastTrackアイコンをクリックします。 ![]()
FastTrackは既存のデータベースでも使用できることにご注意ください。簡単な例について説明します。
最初に、上部のバーでFastTrackオブジェクトに名前を付ける必要があります。
![]()
FastTrackオブジェクトを保存すると、常にドロップダウンリストに表示されます。
新しいFastTrackオブジェクトを作成したり、名前を変更したり、別の名前で保存したり、既存のオブジェクトを削除したり出来ます。
FastTrackはトラックを作成し、[新しいトラックを追加(Add new Track)]コマンドを使用してトラックリストに追加するためのトラックの集合です。直接名前をクリックしてトラックの名前を変更出来ます。
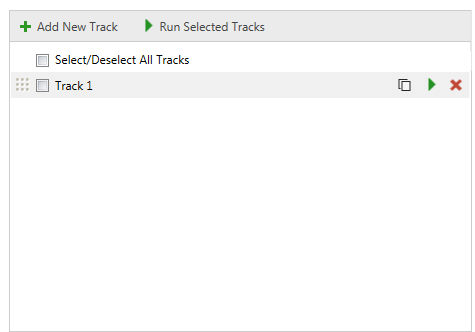
チェックボックスをクリックしてさまざまなトラックを選択出来ます。これにより、[選択したトラックを実行(Run Selected Tracks)]をクリックして、毎回複数のトラックを実行出来ます。
トラックの横にある[このクエリを実行(Run this Query)]アイコン![]() を使用して、単一のトラックを実行できます。
を使用して、単一のトラックを実行できます。
その他のアクションには、[クエリを複製(Duplicate Query)]![]() 及び[このクエリを削除(Remove this Query)]
及び[このクエリを削除(Remove this Query)]![]() があります。
があります。
ここで、データソースを選択します。データソースの作成は、SQLデータリーダーでの場合とまったく同じであるため、ここでは説明しません。
![]()
いったんデータソースに接続すると、SQLステートメントを使用してクエリを定義出来るように、テーブル及びビューのリストが表示されます(以下の例を参照)。
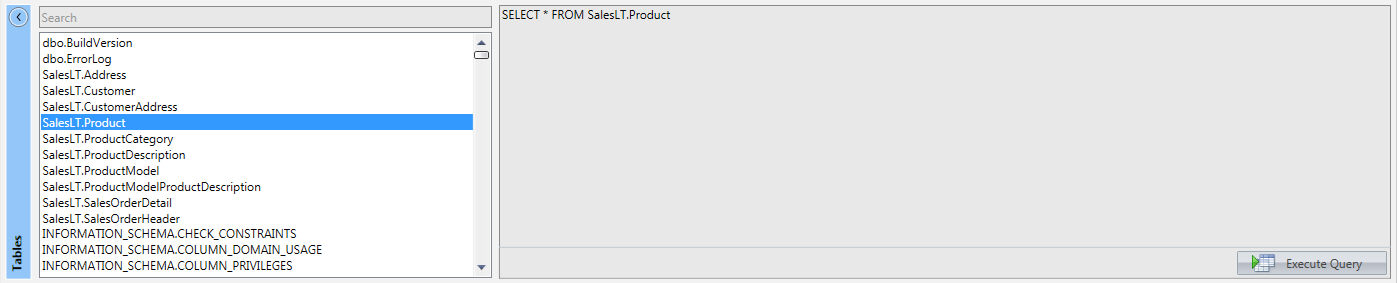
テーブルをダブルクリックすると、デフォルトのクエリが生成されます。
SELECT * FROM <テーブル名>
このパネルの右下にある[クエリを実行(Execute Query)]をクリックして、一番下のテーブルにフィードします。
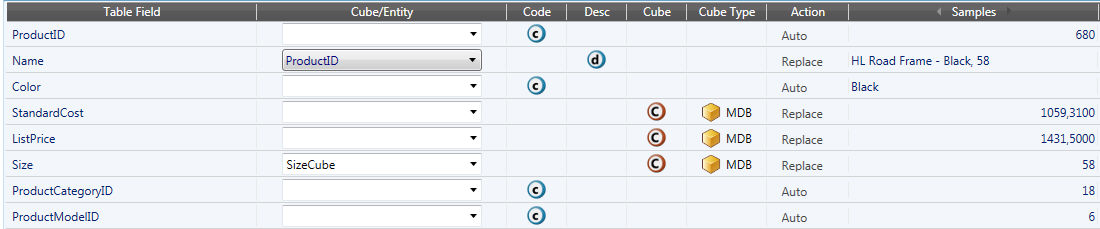
トラック定義の例
[テーブルフィールド(Table Field)]: クエリを行ったSQLテーブルの列名を示します。
[キューブ/エンティティ(Cube/Entity)]:フィード/作成されるキューブ/エンティティの名前。 これを空白のままにすると、デフォルトの選択になります。 デフォルトの選択は[テーブルフィールド(Table Field)]です。 このフィールドは[説明(Description)]行の場合は空白のままには出来ません。[説明(Description)]行は(既存又は同じトラック内で作成された)エンティティと関連付けられる必要があります。
[コード(Code)]:SQL列にエンティティコードが含まれている場合は、これを選択します。
[説明(Description)]: SQL列にエンティティの説明が含まれている場合は、これを選択します。
[キューブ]:これが値列である場合は、キューブを選択します。キューブが作成されます。 キューブの名前は2つ目のフィールド内にあり、構造は、コードを使用するか又はトラックによって簡単に読み込んで作成/フィードされたすべてのエンティティにより指定されます。
[キューブタイプ(Cube Type)]: MDB/RDB。
[アクション(Action)]: データリーダーと同様に、このフィールドで[追加]モードと[置換]モードを設定出来ます。 コード列では、以下のいずれかを選択出来ます。
[追加] - このコードを持つアイテムが存在しない場合は、アイテムが作成され、キューブのロード時にそのレコードが考慮されます。
[ブランク] - 不明なコードによりレコードが拒否されます。
[自動] - 自動モード。エンティティの存在に基づいて自動的に決定が行われます。
キューブ行で、[ブランク](同じ交点にある値を合計します)又は[置換](古い値を新しい値で置き換えます)のいずれかを選択出来ます。 [説明(Description)]でも、既存の説明を変更しない[ブランク]か、ロードしたものにより既存の値に置換する[置換]のいずれかを選択出来ます。
[サンプル(Samples)]: この列には最初にクエリされた行が表示されますが、ヘッダにある2つの矢印キーを使用して以降のクエリにスクロール出来ます。
[詳細オプション(Advanced Options)]は、FastTrack画面の右上にあります。4つの詳細オプションを設定出来ます。
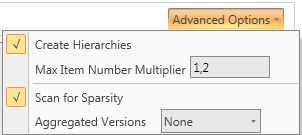
[階層を作成(Create Hierarchies)]:フラグが付いている場合、エンティティの定義とともに暗黙の関係をロードします。上の図では、4つのエンティティをロードしています。[階層を作成(Create Hierarchies)]というフラグが付いたProductID、Color、ProductCategoryID、及びProductModelIDは、自動的にこの種類のツリーになります。
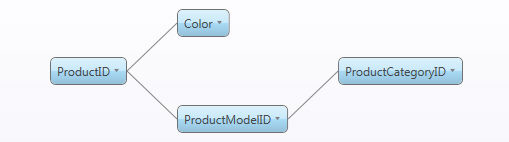
フラグが付いていなければ、関係はロードされません。
[最大アイテム数の乗数(Max Item Number Multiplier)]: 以下のように、最大アイテム数を設定します。各エンティティの最大アイテム数は、(ロードされる総数)×(最大アイテム数の乗数)になります。
[スパース性をスキャン(Scan for Sparisty)]: フラグが付いている場合、FastTrackはキューブのスパース性を自動的に判断します。
[集約されたバージョン(Aggregated Versions)]:最大5レベルのバージョンを設定出来ます。レベルには、キューブのデフォルト以外に追加のバージョンを作成しない[なし(None)]、3つの中間値を経たキューブの考えられるバージョンすべてを作成する[多い(Many)]、[少ない(Few)]、[普通(Normal)]、及び[大量(Huge)]があります。
キューブ、エンティティ、関係以外の、データベースの作成を終えると、FastTrackにより一連のデータリーダーも作成されます。これらのデータリーダーは、FastTrackがエンティティ及びキューブをロードするために使用したものと同じで、トラックの一部分のみを実行する場合に役立ちます(例えば、製品表)。
さらに、FastTrackはマッピングプロパティのおかげで、既存のデータベースを管理したり、新しいデータソースと統合したり、異なるデータソースを結合したりするのにも役立ちます。
例えば、「製品」というエンティティのあるデータベースを考えてみましょう。その製品表が含まれている新しいデータソース「A」から取り出したいくつかのデータを追加しようとしています。FastTrackを使用すれば、製品という既存のエンティティに新しい製品表を素早くマッピングし、2つのリストを結合出来ます(結果として2つのリストの結合体になります)。