クラスタリング
1 はじめに
バージョン9より、Boardはデータクラスタリングの機能を提供します。 これにより、K-Meansというデータマイニングアルゴリズムに関するこのプロセスに基づいて、親エンティティとそのリーフエンティティとの関係が自動的に指定されます。
Boardクラスタは、親エンティティとの関係を作成する特定のエンティティのメンバーをグループ化します。この基準は指定された一連のキューブによって決定されます。 クラスタは、入力キューブに基づいてより類似したメンバーをグループ化します。
1.1 使用方法
親メンバーをホストするエンティティを作成し、クラスタ化する必要のあるものに関連付けます。
BEAMアイコンの下にある[データベース]タブからクラスタセクションを入力します。

クラスタリングシナリオを作成します。ドロップダウンリストから既存のシナリオを選択するか、新規作成することが出来ます。
![]()
· [新規(New)]:新しいクラスタリングシナリオの名前を定義します。
· [名前を変更(Rename)]:クラスタリングの名前を入力し直します。
· [名前を付けて保存]:別のシナリオとして保存します。
· [削除]:シナリオを削除します。
· [実行]クラスタリングシナリオを起動します。
以下では、クラスタ化するエンティティ及びいくつかのモデルオプションについて説明します。

[対象(Tartget)]:新しい別個のカテゴリをホストする対象エンティティを選択します。
[ソース(Source)]: 別個のカテゴリにグループ化されるソースエンティティを選択します。
[ページングオプション(Paging option)]:ページごとにn個の異なるグループ内のソースエレメントをグループ化します。 例えば、[市ごとにページ分けされた顧客(Customers paged by City)]をグループ化する場合、特定の点で類似した顧客を市ごとにグループ化します。その市の上得意を表すグループがあるため、これらの顧客は全体として最良ということではありません。
[リセット]:シナリオを実行する前に、以前のクラスタリング関係をリセットします。
[別個のグループ(Distinct group)]:ページングオプションが有効になっている場合、ページごとにn個のエンティティメンバーを作成します。
[クラスタ(Clusters)]:クラスタの数を定義します。
[グループ(Group)]:対象エンティティメンバーに割り当てるカスタム名を定義します。
[選択] :ソースデータはこの選択によってフィルターされます。
これから、ソースデータについて見て行きます。ソースデータは、エンティティメンバーの類似性を理解するために使用されるキューブ/アルゴリズムの一覧です。例えば、価格、マージン、及び販売個数ごとに製品をクラスタ化する場合、クラスタは3つのエンティティのすべてに対応する製品をグループ化します。 キューブの設定方法を見て行きましょう。
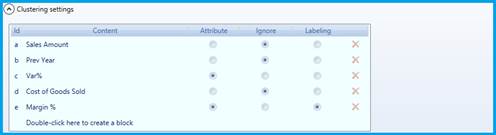
· [属性(Attribute)]:クラスタ用として考慮されるデータ。
· [無視(Ignore)]:計算済みフィールドに含まれているが、クラスタリング計算に適用されないデータ。
· [ラベル付け(Labelling)]:これが見られるシリーズごとにグループを整理します。
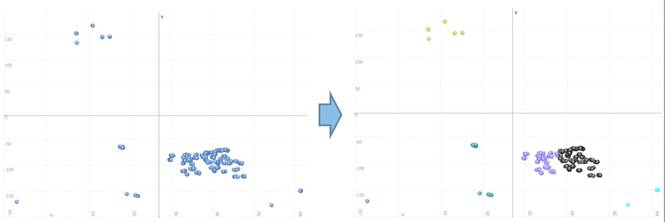
最後のセクションは結果のみを示し、ここから関係を直接確認出来ます。

これは、バブルチャートを使用する2つのキューブのみを使用する場合に、クラスタの効果を確認するための素早い方法です。以下の例では、2つの属性キューブで5つのクラスタを作成しました。