予測解析
1 はじめに
バージョン9から、Boardはユーザが予測を立てるのに役立つ新しい予測エンジン (B.E.A.M.) を提供します。
このツールは、履歴データによって自動的に調整される数学モデルの適用を通して、履歴データに基づいて自動予測を計算します。
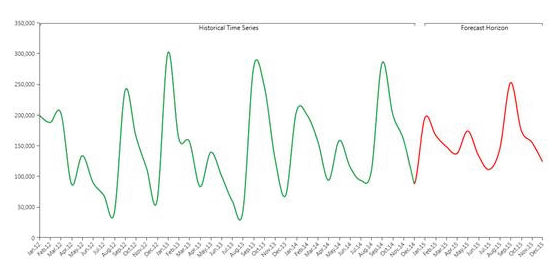
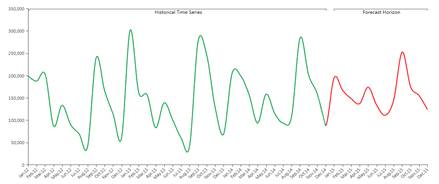
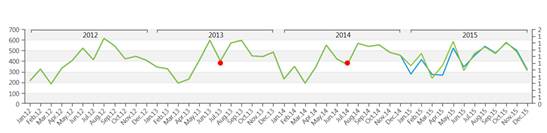
上図は予測解析機能(赤)を通じて将来について予測された履歴データ(緑)の例です。
予測解析ツールの動作は自動ですが、一方では非常に柔軟で、ユーザが予測シナリオに情報を追加し、その予測を改良するのを可能にします。 実際、履歴時系列以外に、ユーザは予測に影響する他の手段やパラメータをB.E.A.M.に供給出来ます。 システムは最初に履歴データに適用する最良のモデルを理解し(学習段階)、その後そのモデルを来るべき時間枠に適用します(予測段階)。
1.1 基本概念
このセクションでは、解析インタフェースをより良く理解し、適切に使用するために、一連の概念を説明します。
1.1.1 フロー
あるソースキューブで予測解析シナリオを実行する場合、エンジンは以下を行います。
時系列を検出する。
各時系列を中断、断続、平滑に分類する。
各時系列の最初にあるゼロを除去し、時系列を整える。
競合によって各系列の最良モデルを割り出す。
異常値を識別する。
有効な共変数を検出して外因性共変数を適用し、モデルを改良しない共変数を破棄する。
将来再使用するためにモデルをシリアライズする。
この部分は学習部分であり、 一旦完了するとシステムはモデルを将来値(予測期間)に適用し、各種インジケータを出力します。この部分が予測部分です。
ここで上記の概念(時系列、異常値、共変数…)を1つずつ全て説明します。このプロセス全体は自動で、ユーザは何が起こっているかを認識できないことに注意してください。ユーザはプロセスの出力が揃ったときに通知されます(以下を参照)。
1.1.2 時系列
一般に、時系列は時間エンティティ(日、週、月)に関する値のリストです。
ここで、市、製品及び月から構成されるキューブ(観測キューブ)内のデータを予測したい、しかし地域、製品グループ及び月レベル(ターゲットキューブの構成)で予測したいという場合を考えてみましょう。 時系列は全て、ソースキューブの地域及び製品グループのゼロではない組み合わせとなります。 すなわち、レイアウトで行に製品グループ及び市を入力し、列に月を入力した場合、各行は時系列を表します。
時系列の数は粒度と呼ばれます。
1.1.3 時系列分類
時系列には、中断、断続及び平滑の3種類があります。
中断
明らかにゼロである場合(前年のデータは常にゼロ)、時系列は中断となります。

断続
頻繁にゼロになっていても、ある期間には値がある場合、時系列は断続となります。 例えば、大きな機械を販売している場合、毎月販売するとはいかなくても、1年に2回ならあり得ます。 そのような時系列が断続です。 厳密に、時系列のゼロではない2つの値の間の平均経過時間(期間内)を計算します。この値が1.3を上回る場合、時系列は断続です。
平滑
どの期間でも値がかなり大きい時系列は平滑と定義されます。基本的に断続又は中断ではない時系列はすべて平滑です(ゼロではない2つの値の間の期間内平均経過時間は1.3未満)。
1.1.4 モデル
中断時系列は将来でもゼロと想定されるので、この種の時系列のモデルは全ての期間で値がゼロでしかありません。 断続時系列は予測に Croston-SBA モデルを使用します。 このモデルの性質により、将来の予測は全ての時期で定数になります。

平滑時系列の場合は、少し複雑になります。 時系列のモデルはIdsi-ARXと呼ばれています。 このモデルはARIMA ファミリの一部です。 ARIMAは競合を通じて時系列に合わせられます。時系列は期間の長さ0.75で切り捨てられます。最初の部分はARIMA の計算に使用され、残りの部分はベンチマークとして使用されます。 最も適合するモデルが選択されます。 競合で、2つの 単純予測変数もあります。持続的なもの(常に時系列の最後の値)及び季節的なもの(基本的に前年)です。 競合で勝ったモデルが選択され、データを全て入力として使用しながら、将来値を計算するのにも使用されます。 下図は競合の概念を示しています。緑色の系列はオレンジ色及び青色の系列とともに予測されています。青色の系列は(平均平方誤差で)元の系列により近いので、オレンジ色の系列に対して青色の系列が選択されます。
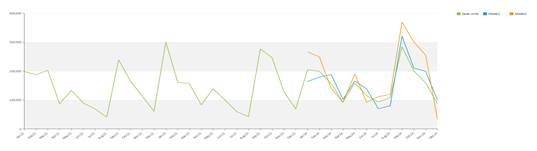
モデルが選択されると、そのモデルを採用して予測が計算されます。
1.1.5 異常値
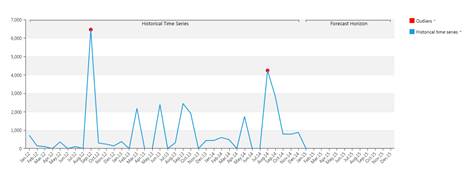
システムは履歴データの中のいわゆる「異常値」も検出します。 モデルに対する誤差が標準偏差の3.5倍を上回る場合、その時系列値は異常値となります。
1.1.6 共変数
共変数は観測時系列にいくらか関連した計測期間(将来及び過去)全体に適用できる時系列です。 例えば、イースターエッグ販売者の場合、イースターの期間は時系列が1と定義され、それ以外の0は共変数です。 システムは、この共変数が時系列に与えた効果を評価し、共変数に意味がある場合にのみ、それを将来に適用します。共変数の効果が予測に含まれることで大きな予測誤差が起こった場合、共変数は破棄されます。 共変数はブールの(サンプルのように)又は別の時系列になることがあります(例えば、アイスクリーム売上高の時系列を観察している場合、平均温度が共変数になる)。 共変数について将来値を設定することは必須ではありません。 過去のある期間にイースターエッグの店が休業していても将来は休業しないことがわかっている場合、その期間に何か起こっていたこと、そしてそれが将来起こらないことをシステムに伝えるのみです。
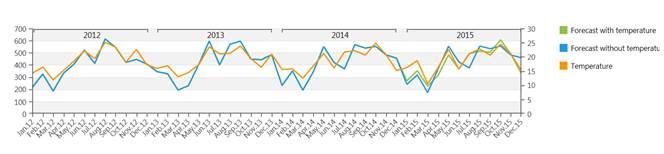
例1:
温度共変数あり、または無しでのアイスクリーム売上高の予測(予測期間は2015年)
例2:
特定の期間におけるアイスクリーム販売促進キャンペーン(過去及び将来のブール共変数、予測期間は2015年)

例3:
アイスクリーム店は過去に2回、丸一ヶ月休業していたが、このようなことが再び起こるとは考えられない(過去のブール共変数)。 緑色の時系列は共変数を考慮しているが、青色の時系列は考慮していない。
共変数は好きなだけ適用でき、制限はありません。
1.1.7 予測間隔
信頼度をXとすると、予測間隔は確率Xのときの予測値のn倍の期間になります。
すなわち、信頼度90%を設定すると、システムは予測された期間に対し、下限値と上限値を提供します。 将来の観測値は、確率90%のときの下限値と上限値の間になります。
例:
2015年末に、値の90%が以下のグラフの青色のエリアに入っているのが見られる。

1.1.8 調整
複数のバージョンのキューブがある場合、予測分析は各バージョンについて別々のシナリオを考慮しながら調整を行います。
最も詳細なバージョンの予測の合計は、それほど詳細ではないバージョンの予測と異なりますが、これはターゲットキューブが整列していないことを意味します。
キューブを整列しないままにするか又は調整を行うかを選択出来ます。
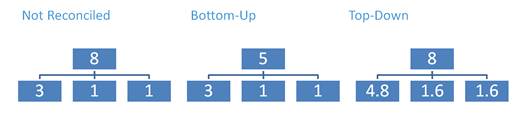
調整は2種類あります。トップダウン及びボトムアップです。
トップダウン:集合バージョンのデータを、最下位バージョンのセル値に比例させて最下位バージョン(Split&Splatと同様)に割り当てます。
ボトムアップ:キューブを整列させます。
1.1.9 誤り統計
システムは各種誤差を計算します。
MAE (Mean Absolute Error:平均絶対誤差): 観測とその予測の間の絶対誤差の平均です。 この測定はスケールに依存しています。
MAPE (Mean Absolute Percentage Error:平均絶対パーセンテージ誤差): 誤差の平均絶対パーセンテージサイズです。 この測定はスケールに依存していません。
MASE (Mean Absolute Scaled Error:平均絶対スケール誤差): MAEと単純モデルのMAEとの比率です。 スケールに依存しておらず、単純モデルと比べて予測がどの程度優れていたかを測定します。 1より大きいMASE は、選択されたモデルが単純モデルよりも機能しなかったことを示し、1未満の場合は選択されたモデルが単純モデルよりもよく機能したことを示します。
全体加重MASE: この計測は、各種時系列の全てのMASEインジケータの加重平均です。
2シナリオ作成
適切なライセンスがあるユーザの場合、[データベース]タブに表示されます。
シナリオコンフィギュレータが開きます。以下の図を確認し、各部を理解してください。
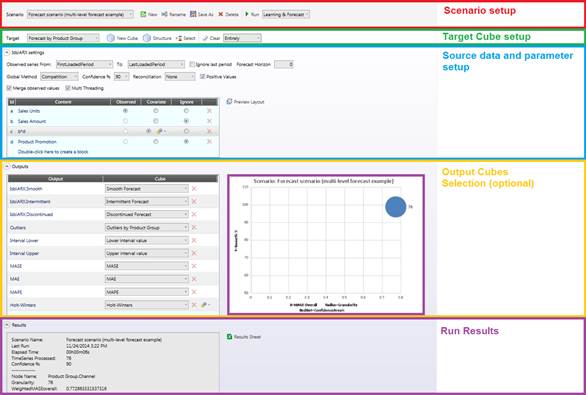
2.1シナリオ設定
![]()
左側のドロップダウンリストから編集又は実行するシナリオを選択します。シナリオを複製して名前をつけることもできます。 右側のドロップダウンリストで、システムが実行時ごとに再度学習段階を実行すべきか又は予測段階のみを実行すべきかを決定することができます。
最初の実行の前に学習及び予測の両方を実行し、ドロップダウンリストを無効化しなければならないことに注意してください。 性能改善の場合のみ、学習を行わずにシナリオを起動します。
2.2ターゲットキューブ設定
![]()
予測データを得るキューブを選択します。キューブは高密度な構造でなければなりません。ここで新しいキューブを作成したり構造を編集したり出来ます。複数のバージョンを持つことが出来ます。
[選択]で予測計算が実行される時系列が絞り込まれます。[時間で選択(Select on Time)]次元は利用できません(次のセクションを参照)。
予測計算の間にキューブ全体をクリアするか、現在の範囲のみをクリアするかを決定することも出来ます。
ターゲットキューブは時間次元及び予測粒度を決定します。
例:
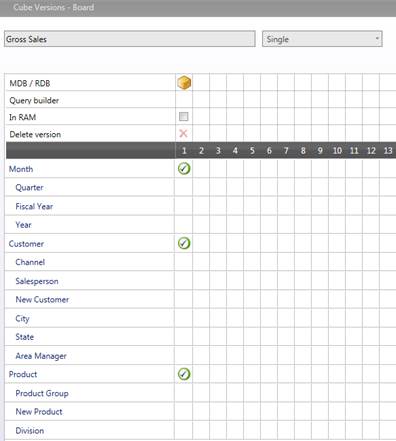 a
a
ソースデータの顧客及び製品の事前設定された組み合わせはどれでも時系列を表します。時系列は月がベースです。
2.3 入力データ及びモデル設定
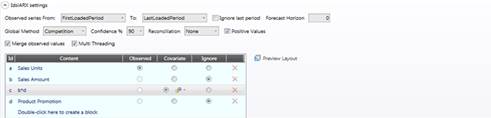
このセクションはシナリオ設定に最も重要です。予測の精度は主に履歴データセットに依存します。
2つのドロップダウンリストで、どの期間を観測するか選択出来ます。デフォルト値は以下の通りです。
FirstLoadedPeriod: 選択にあるキューブの最も古い値: この値は独自のもので、各時系列について評価されないことに注意してください。
LastLoadedPeriod:選択にあるキューブの最新値: この値は独自のもので、各時系列について評価されないことに注意してください。
最後の期間のデータが完全でないと思ったら、[最後の期間を無視(ignore last period)]チェックボックスにフラグを付けて除外します。
予測期間(Forecast Horizon): ここで予測したい期間の長さを決定出来ます。デフォルト値の0の場合、期間範囲の最後まで予測が行われます。
包括的方法(Global Method): 競合を通じてモデルを得るか、2つの単純予測変数のうち1つを強制するかを決定出来ます。
信頼度(Confidence):ここで上限間隔及び下限間隔の計算の信頼度を決定します。
調整(Reconciliation): 3つの調整タイプのうち1つを選択します。これは複数バージョンのターゲットキューブの場合のみ必要とされます。
正値(Positive values): ある期間に負の結果を出すモデルを全て自動的に破棄したい場合、これにフラグを付けます。
観測値をマージ(Merge observed values): この設定がオンの場合、履歴データは予測とともにターゲットキューブにコピーされます。
マルチスレッド(Multi Threading): このフラグは計算結果に影響しません。マルチスレッドをサポートしている機械の計算性能を改善します。
ソースレイアウトに移りましょう。
ここで、ソースデータとして使用するキューブ及びアルゴリズムを決定出来ます。
キューブ及びアルゴリズムは以下のように設定出来ます。
観測(Observed):観測キューブ/アルゴリズムは1つしか存在出来ません。これは予測しようとする数量です。
共変数(Covariate):好きなだけ共変数を持つことができます。共変数は観測時系列にある種の影響を持つ計測期間全体の値を持つ時系列を含むキューブです(例えば、アイスクリームの売上高を観測している場合、月ごとの平均気温を使用出来る)。共変数の最遅を決定することもできます。これは特定の期間の共変数値に影響される前後の期間の最大数です。システムは予測に利益を与えない共変数を破棄します。ギアアイコンをクリックすると共変数の採用を強制できます。
ブロックを破棄しますが、無視します。
右上隅のボタンをクリックするとこのレイアウトをプレビュー出来ます。 行で時間枠のレイアウトをプロンプトします。
2.4 出力
ターゲットキューブの予測以外に、予測分析は多くのデータを出力します。 必要に応じて、このデータを一連のキューブに入れることを決定出来ます。
出力キューブはターゲットキューブのように必須ではありません。それらの構造はターゲットキューブと同じです(構造が異なっている場合、自動的に変換される)。
IdsiARX.Smooth: このキューブは平滑時系列のみを含むターゲットキューブの一片です。
IdsiARX.Intermittent: このキューブは断続時系列のみを含むターゲットキューブの一片です。
IdsiARX.Discontinued: このキューブは中断時系列のみを含むターゲットキューブの一片です。
異常値: このキューブは各種時系列の異常値とともに過去を踏まえてのみ事前設定されます。
下限間隔: このキューブは予測の下限を含みます。確率が信頼度と同等な状態で、実測値は下限間隔よりも大きく、上限間隔よりも小さくなります。
上限間隔: このキューブは予測の上限を含みます。 確率が信頼度と同等な状態で、実測値は下限間隔よりも大きく、上限間隔よりも小さくなります。
MASE: 各時系列のMASEを含むキューブです。期間のMASEはその期間までの時系列に対するモデルのMASEです。
MAE: 各時系列のMAEを含むキューブです。期間のMAEはその期間までの時系列に対するモデルのMAEです。
MAPE: 各時系列のMAPEを含むキューブです。期間のMAPEはその期間までの時系列に対するモデルのMAPEです。
ホルトウィンタース: 三重指数平滑法としても知られています。時系列の三重指数平滑を出力します。 アルファ、ベータ、ガンマパラメータを直接インタフェースから設定出来ます。 ホルトウィンタースは、ブロックエディタの予測時間機能の下のアルゴリズムであることに注意してください。
2.5 実行結果
各実行の後で、実行時間、時系列の数、全体加重MASEの統計を得ます。平滑時系列の数に対するMASEを描くグラフも表示されます。
2.6 プロシージャ経由でシナリオを実行する
プロシージャから予測分析シナリオを実行することも出来ます。

ユーザはシナリオの実行をプロシージャ選択又はシナリオ選択及び学習計算Y/Nで行うかを決定出来ます。