データモデリングについて
Boardのデータモデルの実装は、エンドユーザーの要件を収集および分析し、多次元データモデル仕様を定義するフェーズとなります。
なぜ多次元なのか?
リレーショナル・データ・モデルに基づく業務システムは単一のトランザクション単位で保存・処理するものとして作られますが、意思決定者にとって必要な情報はトランザクションの詳細ではありません。
意思決定のために必要な情報を得るには、トランザクションの詳細データを集計する必要があります。そのため、リレーショナル・データ・モデルにおけるデータの集計には、以下のような複雑な計算が必要になる場合があります。
- 適切なデータをすべて探し出す
- データをグループ化する
- 各グループのデータを集計する
多次元データモデルは、あらゆる次元のレイヤーを指定して高速に検索できるようデータが集約されていることから、非常に高いパフォーマンスを発揮します。つまり、複雑なビジネスインテリジェンスソリューションで必要とされる大規模なクエリに容易に耐えることができるのです。
多次元分析では、異なる視点(スライス&ダイス)やデータ構造に基づく異なるレイヤーから情報を見ることもできます。このアプローチにより、思い通りのデータを抽出し、可視化することができます。
Boardの多次元データモデルの柔軟性、適応性、拡張性により、プロダクトライフサイクルステージを素早く何度も循環させることで、反復性の高い開発アプローチを採用することができます。
従来のウォーターフォールモデルで考えると、各プロジェクトのライフサイクルステージは通常次のようになります。
- 要求分析
- 設計
- 実装
- テスト
- 納品
- フィードバック
Boardは、実装からフィードバックに至るまで、すべての段階を大幅に短縮します。
Boardデータモデル
すべてのBoard データモデルは、以下の3つの要素で構成されています。
- エンティティ:コードやテキストで定義される情報の集まりです。例えば、1つのエンティティの中には、Customer、Product、Cityのリストが含まれることがあります。エンティティ(および階層)は、キューブの軸となります。
- 関係(階層):2つ以上のエンティティが多対1の関係を持つ場合、関係(または階層)を定義することができます。例えば、CustomerとCity、CityとStateの間にはN:1の関係があるため、Customer → City → Stateという関係に整理することができます。
- キューブ:キューブには、さまざまな次元や階層レベルで分析・表示できるデータ(数値のほか、テキスト、ファイル、日付など)が格納されています。
Board は、ディメンションによって編成されたセルで構成されるキューブと呼ばれる多次元オブジェクトにデータを整理して保存します。Board のデータモデルでは、ディメンションとは、キューブの軸として使用できる独立したエンティティまたは関係全体を指します。ディメンションは、ユーザーにとって関心のある領域(月、顧客、製品など)に関連してデータを分類・構造化します。
例えば、エンティティ「通貨」は、「受注額」や「請求額」といったキューブのディメンションになることができます。
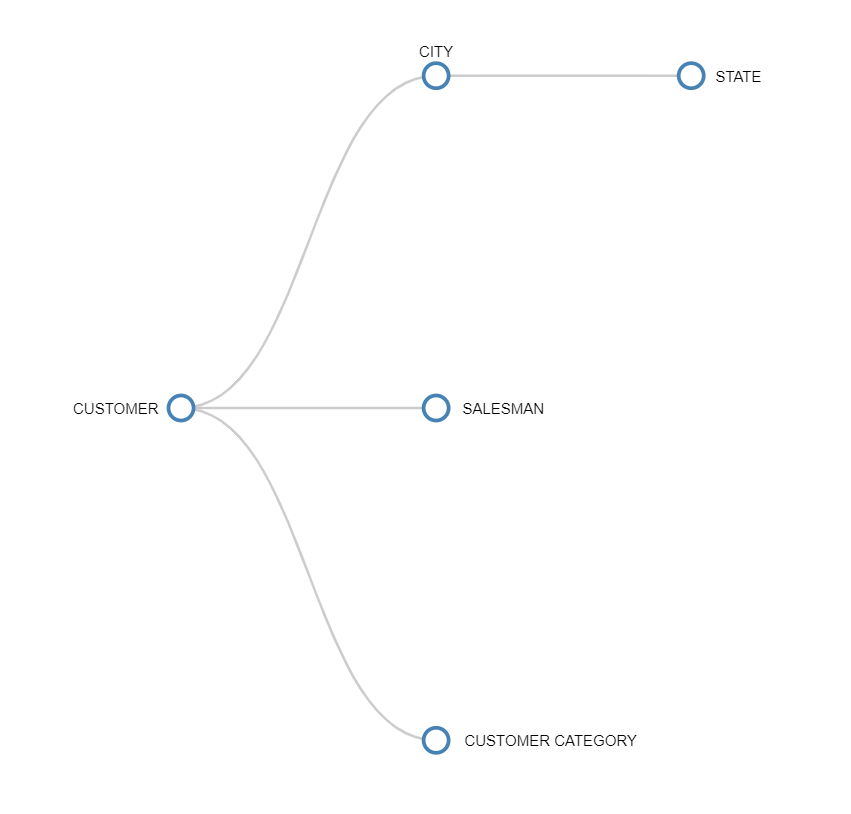
Customer、City、State など、階層的に関連する 3つのエンティティも、Customer ディメンションと呼ばれる一意のディメンションを形成します。このシナリオでは、ディメンションは関係のベース・レベル・エンティティ、つまり最も詳細なレベルのエンティティにちなんで命名されます。
次のツリー図は、典型的な関係を表しており、Customer エンティティは、別のブランチに属する異なるエンティティと関係が繋がっています。
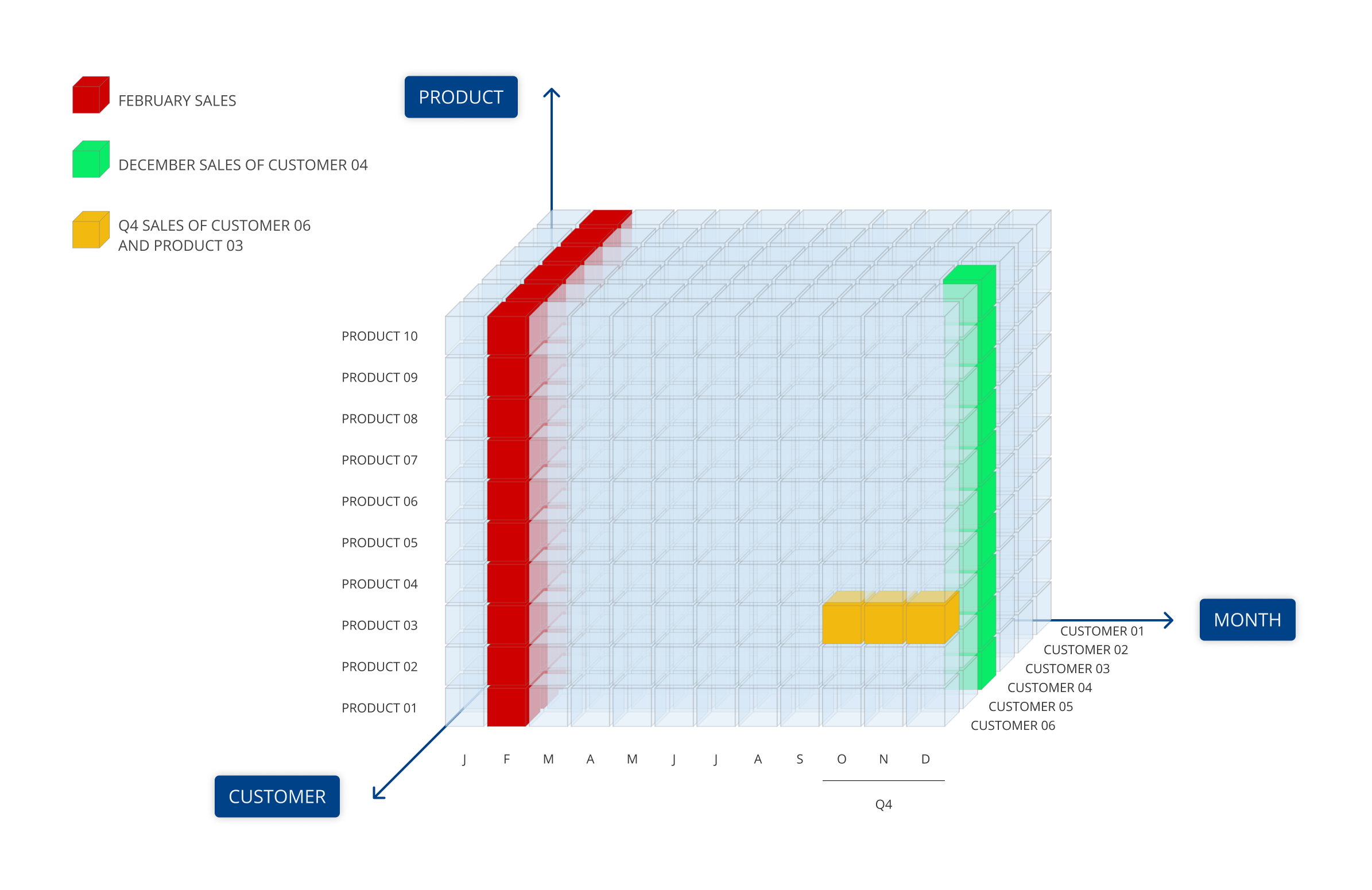
キューブ内の最小の単一項目はセルと呼ばれます。各セルは、キューブの各ディメンションの各1メンバの一意の論理交差 (座標) を表します。
例えば、"sales" キューブでは、セルに売上値が含まれ、製品 (製品ごとの売上高)、地理 (国別の売上高)、時間など、さまざまな次元で表示することができます。
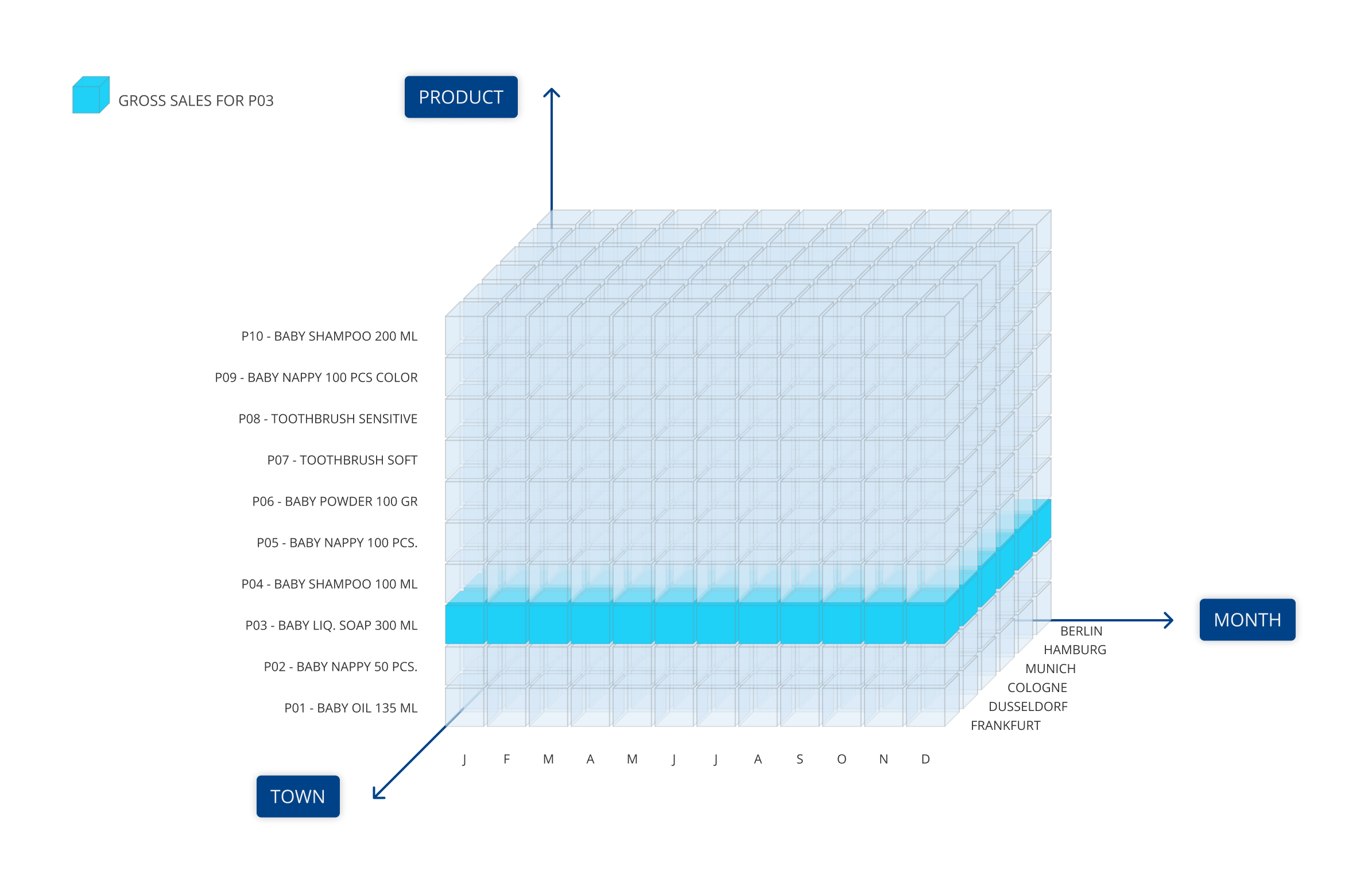
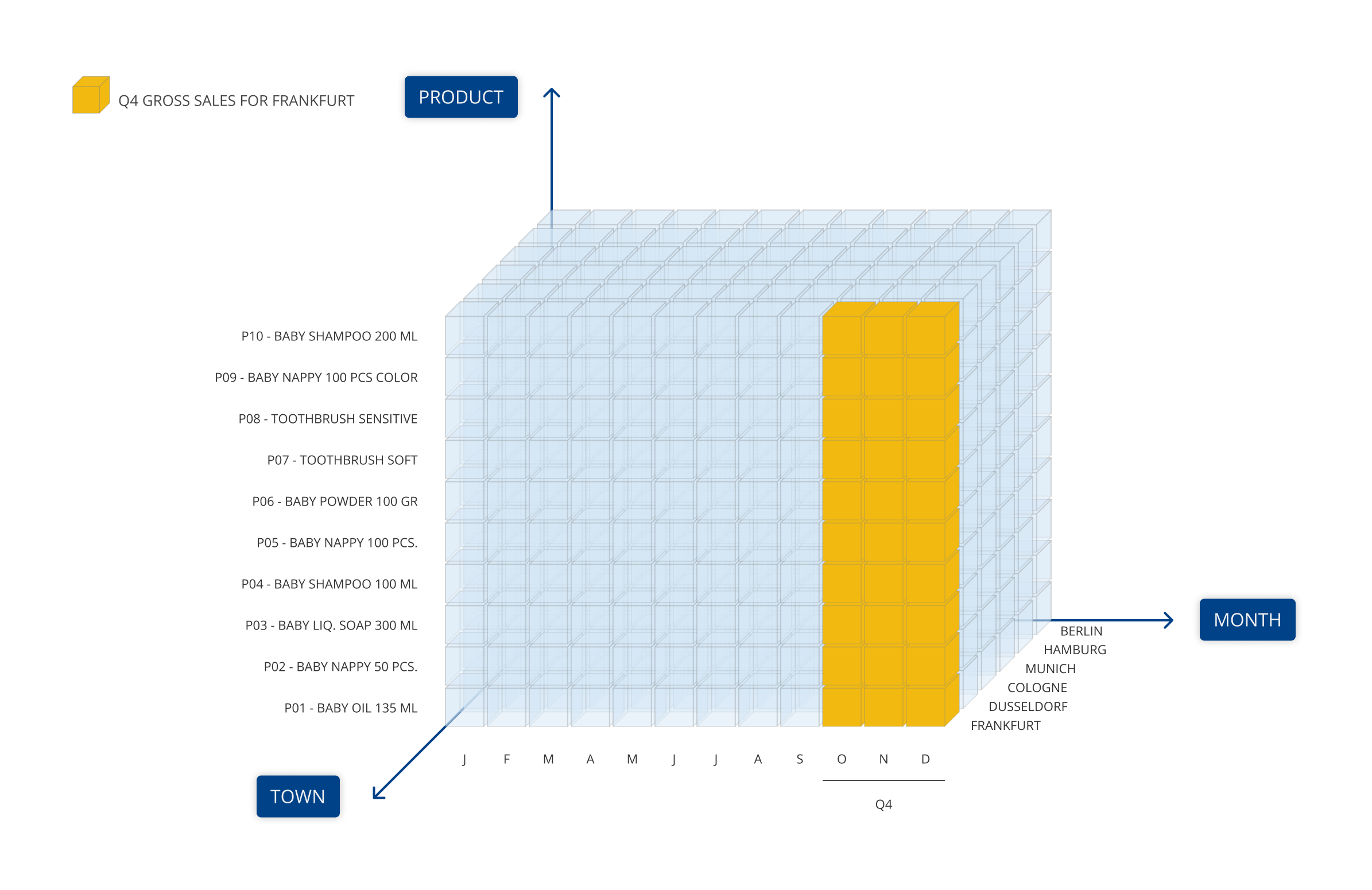
エンティティは、関係によってリンクされ、異なる集計レベルでデータを表示するために使用される階層構造(例:製品→製品グループ→製品部門)を確立することができます。不規則階層は、各要素が親子関係で構成される階層的なデータ構造全体を収容することができる特別なエンティティです。
エンティティ、関係、キューブは、企業の多次元データモデル、より一般的にはモデル化されたシステムを形成します。モデル化されたシステムは、Boardで表示・操作したいビジネスの各側面を表しています。
要約すると、Board のデータモデルは、以下のような構成になっています。
- エンティティ:コードやテキストで定義される情報の集まりです。例えば、1つのエンティティの中には、Customer、Product、Cityのリストが含まれることがあります。エンティティ(および階層)は、キューブの軸となります。
- 関係(階層):2つ以上のエンティティがN:1の関係を持つ場合、関係(または階層)を定義することができます。例えば、CustomerとCity、CityとStateの間にはN:1の関係があるため、Customer → City → Stateという関係に整理することができます。
- キューブ:キューブには、さまざまな次元や階層レベルで分析・表示できるデータ(数値のほか、テキスト、ファイル、日付など)が格納されています。
データモデルの実装
データモデルの実装プロセスの主なフェーズは以下の通りです。
- 新しいデータモデルの作成と時間範囲の定義
- 必要なエンティティの作成
- エンティティ間の関係を定義して階層を作成する。
- 必要なキューブの作成
- データソースからエンティティ、関係、キューブにデータをロードする。
新しいデータモデルを作成する際には、各フェーズが前のフェーズに直接依存するため、この順序に従うことが重要です。エンティティは各キューブの構造を形成し、関係はキューブに格納されたデータの特定の詳細レベルを定義することでより集約的なレベルでクエリを実行することを可能にします。
キューブのディメンションとして設定された関連性のないエンティティは、膨大な数の組み合わせ(セル)を生成することがあり、組み合わせごとにデータをロードする必要があります。関係が構築されていれば、関係で繋がった親階層の値は暗黙のうちに計算されます。一方、エンティティ間の関係を適切に定義しなかった場合、キューブ内のデータに矛盾や不要な冗長性が生じ、レポートに誤った値が表示されることがあります。
データモデルにデータを取り込むと、ユーザーはデータソースに関係なく、キューブの読み取り、書き込み、更新を行うことができます。
Boardは、キューブだけでなく、リレーショナルデータソースへのライトバックをサポートしており、業績管理プロセスをエンタープライズアプリケーションと効果的に統合することが可能です。
Boardは、複数のデータを接続、統合、連携する機能を提供します。
- リレーショナルデータベースとデータウェアハウス
- エンタープライズアプリケーション(例:SAP ERP)
- 多次元ソース(SAP BWを含む)
- APIコールによるWebサービス
- Excel、CSV、TXTファイル
- クラウドベースのソース
データは通常、データリーダーを経由してBoardにインポートされます。データリーダーは、データとエンティティのマッピング、関係、キューブを処理します。
インポートされたデータは、データモデルプロシージャを使用して、後で操作することができます。
技術的な観点として、Board は外部ソースからデータをインポートするために以下のデータプロバイダを利用しています。
- リレーショナルデータベースと接続するための Open Database Connectivity (ODBC) 標準と OLE DB
- CSVファイルおよびTXTファイル